
使用Word2Vec进行同义词检测
 MartinLiebig
管理员,主持人,员工,RapidMiner认证分析师,RapidMiner认证专家,大学教授职位:3297年
MartinLiebig
管理员,主持人,员工,RapidMiner认证分析师,RapidMiner认证专家,大学教授职位:3297年介绍了Word2Vec扩展到RapidMiner市场!
我们最近在我们的市场上发布了一个新的扩展:一种用于文本挖掘的高级算法Word2Vec.核心操作符被调用Word2Vec可以被认为是学习者。在接下来的文章中,我将简要地解释其中的基本原理Word2Vec如何以及如何在你的RapidMiner文本挖掘过程中使用它。
是什么Word2Vec
文本挖掘的关键问题之一是单词之间的距离很难定义。人们也可以说:“无论如何,单靠文字是很难计算数学的。”例如,像beautiful和gorgeous这样的单词,它们的意思相似,但拼写却非常不同。算法怎么知道“beautiful”和“gorgeous”的意思是一样的呢?或者它们有相似的内涵,但有不同的含义?
Word2Vec是一个词向量算法,试图解决这个问题。正如标题所暗示的,这个运算符取一个单词并将其转换为一个向量。那么Word2Vec有什么特别之处呢?最酷的地方在于这个新Word2Vec向量可以与单词的“意思”联系在一起.例如:
1.让我们从原始文本中选取一个句子:RapidMiner有一个名为Word2Vec的新扩展
2.现在让我们“窗口化”我们的句子,总是把中间的单词省略掉:
RapidMiner有___新的扩展
有一个___extension叫做
新扩展___ Word2Vec
3.Word2Vec定义一个概率P对于缺少的单词,取决于周围的单词.事实上,Word2Vec为每个单词分配了一个向量。整个把戏Word2Vec它优化了所有的向量条目,使正确的空白词的概率最大化,并使其他空白词的概率最小化。这样它就为每个单词分配了一个向量。
样本过程Word2Vec
有多种方法可以使用Word2Vec作为数据科学过程的有用补充。乐鱼平台进入在这个示例过程中,我们将从TripAdvisor评论数据(可用)创建一个自定义词干字典在这里).所有描述的过程都附在这篇文章中。
我们的分析分为三个部分。第一部分读入数据并将其转换为文档集合。每个文档都已经标记了。第二个进程将创建一个Word2Vec最后的第三个模型是生成词干字典。
第一步:阅读和标记化
每个酒店的数据在一个平面文件中提供,结构如下:
<综合评分> 4
< Avg。价格> 302美元
< URL >http://www.tripadvisor.com/ShowUserReviews-g60878-d100504-r22932337-Hotel_Monaco_Seattle_a_Kimpton_Hotel-Seattle_Washington.html
< >作者selizabethm
<内容>美好的时光-即使有雪!多么棒的经历啊!从房间里的金鱼(我女儿很喜欢)到代客停车的工作人员为我戴上链子,这真是太棒了。工作人员很细心,竭尽全力使我们在这里过得很愉快。哦,关于停车:收费是你在任何车库或停车场支付的费用-我敢打赌他们不会在雪地里帮你!
<日期> 2008年12月23日
<没有。读者> 1
<没有。帮助> 1
整体> < 5
< >价值4
<房间> 5
<位置> 5
<清洁> 5
<入住/前台>
<服务> 5
<业务服务> 1
我们使用循环文件+读取文档组合读取所有文件,然后使用Cut Document操作符循环所有文档以仅提取内容。在剪切文档中,我们快速地将所有标记转换为小写并标记化我们的文档。将集合压缩为一个直接的文档集合后,我们将其存储在存储库中以供以后使用。
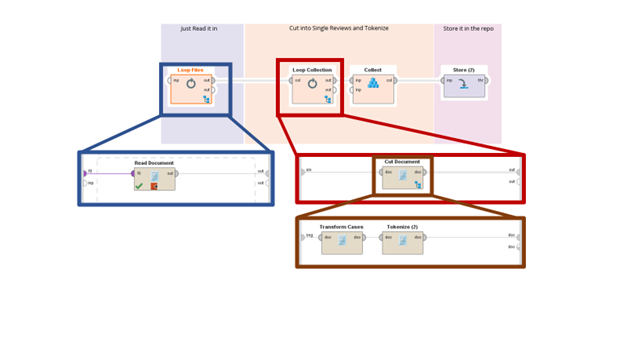 读入过程
读入过程
第二步:训练模型
训练一个Word2Vec模型很简单:获取数据,应用Word2Vec,并存储结果。图层大小(定义一个向量的长度)设置为适中的100,窗口大小设置为7。迭代参数被设置为一个较大的50,这将确保收敛。 培训过程
培训过程
步骤3:构建词干字典
构建最终的字典需要少量的后期处理。新的操作符Extract Vocabulary能够为所用语料库的全部或部分提取向量。使用交叉距离,可以得到在余弦相似测量词向量之间的距离。
在后处理中,我们首先需要删除在交叉距离中创建的重复单词。
之后是另一种类型的副本。这些是第一个例子中的第一个单词等于第二个例子中的第二个单词,反之亦然。
Word1 Word2
华丽的美丽
美丽的漂亮的
 带有创建词干字典的后处理的最终处理过程
带有创建词干字典的后处理的最终处理过程
最后,我们在相似度上应用一个阈值来生成一个修剪良好的列表。这是由宏控制的,因此也可以从外部使用。我们需要确定的唯一一件事是,一个词不会不止一次成为同义词。我们可以通过去除一些额外的重复项来做到这一点。
让我们看看结果吧!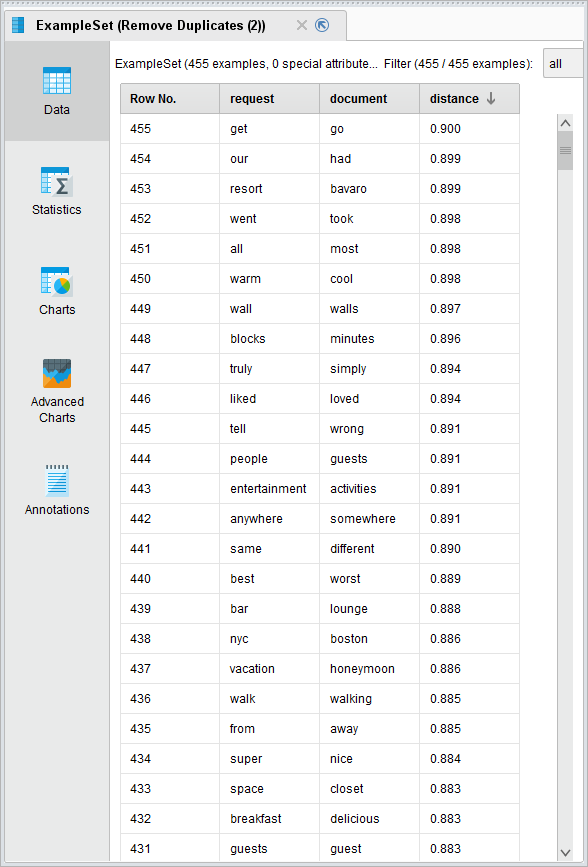 找到同义词的例子,如果你检查结果,你可以看到一些明显的相似之处,如墙而且墙,还有一些更聪明的同义词,比如人而且客人,在任何地方而且的某个地方.
找到同义词的例子,如果你检查结果,你可以看到一些明显的相似之处,如墙而且墙,还有一些更聪明的同义词,比如人而且客人,在任何地方而且的某个地方.
有趣的是,有时具有相反含义的单词被认为是同义词(最好的-最糟糕的,温暖的-很酷的等等)。这是由于方式Word2Vec这些词可以放在相同的空隙中,因此被认为彼此相似。根据你所做的任务,这可能是有用的(例如主题识别),也可能是有害的(例如情绪分析)。对于后者,您需要手动遍历结果列表并删除更多内容。
作为最后一步,我们可以将Aggregate操作符与Generate Attributes操作符结合使用来生成正则表达式。例如:
令人惊叹:太棒了 |
美国:欧洲 |
阿姆斯特丹:柏林 |
和:| |
另:以后 |
在任何地方:某个地方 |
任命:维护 |
区域面积: |
到达:检查|到来 |
问:要求|问 |
该格式可用于您拥有的任何文档。这个操作符被称为“使用示例集的Stem令牌”,是操作符工具箱扩展的一部分。
我在哪里可以了解更多?
德国多特蒙德




评论
非常感谢@mschmitz
为了这个奇妙的过程,现在只是实验。
如果我想分析一组文档,发现不仅是有矢量关系的单个单词,而且还有bigram, trigram短语,这可能吗?或者它会融化你的电脑…
这是否可以与任何其他文本处理或修改相结合,以产生主题的术语桶?
我想知道是否可以通过标点符号分割输入文档。
我正在输入有标题等网页,目前我正在剥离停止词,短字符串4个字母。
因此,我最终得到的只是很长的字符串。
但是,如果我把每个文档按句子或段落/列表内容分开呢?然后,我可以创建许多单独的文档(从一个html页面),可以根据相似性进行分类或分组。
使用文档相似性来处理这些句子。
我将在Word2vec的字典中输出单词,这些单词不仅彼此相关,而且与概念相关(由文档定义为从html文档中提取的句子或列表的相似分组)。
我可能没想对。
我的目标是用一桶单词,然后在一个新的书面文件中,用向量空间来构建段落。不仅是彼此之间,还包括话题范围内的其他单词。
(由预处理使用文档相似性定义的桶)而不仅仅是彼此相关的单个单词。
我以前使用ITF/TO,它可以找到bigrams和triram字符串,并将它们放在页面上。
然而,问题是一样的,你在页面上结束了短语,但不一定靠近彼此。
它的工作,关于创建统计上相似的页面(谷歌),但它非常耗时,有大量的手工修剪。
然后,您必须post处理文档的同义词,以确保您没有过度使用它。
我想创造一种过程,把几个过程缝合在一起ITF/TO Word2Vec,文档集群,LSI产生某种单词的主分组。
这样就只需要把n个单词组合起来,从中形成一个有意义的段落。
提前知道它满足了所有条件。
我买了这本书,还没有拿起来")
也在看这个。lda2vec
https://multithreaded.stitchfix.com/blog/2016/05/27/lda2vec/#topic=5&lambda=1&term=
这在rapidminer中可能吗??
把李
嗨@websiteguy,
首先,谢谢你的夸奖和使用接线员。当人们使用你写的工具时,总是很酷的。
让我们来看看你的问题
Word2Vec本身不支持bi_grams。但也许你可以使用process_documents找到频繁的双引号,并使用Replace令牌将例如not good替换为not_good,然后在Word2Vec中将not_good视为一个单词。
当然,剪切文档应该可以做到这一点。
在运算符中,你可以把整个句子当作单词来处理。这也包括标签或部分代码。我唯一担心的是,你需要足够的样本量。
我会考虑用余弦相似度来聚类向量。
以前从未见过这个,但是谢谢你的链接!目前还不支持,但我们可以对此进行研究。对于最近在工具箱中发布的LDA操作符来说,python的LDA vis包似乎是一个很好的资源。
欢呼,
马丁
德国多特蒙德
嗨@mschmitz
谢谢你的快速回复,
通过剥离停止词并转换为双格或三元组,创建一个文档,然后收集并保存?
然后用连接_处理这些两到三个单词的字符串,它们每个都将是向量中使用的字符串,对吗?
-----------
我正在创建一个新文档
通过在创建时包含这些word2vec结果,这与原始文档集具有统计相似性。
(我发现ITF/TO工作,但它不允许距离,所以你必须盲目地确保包含在原始文档中出现的两格/三格,以确保相似性。即使这样,您也必须在以后的日期返回到您的文档,并改变字符串的用法,以便接近其他bigram字符串。
...
如果对我们新创建的文档、原始文档集和随机的其他文档集进行聚类,新文档会和原始集合落在同一个簇中就像“原版。
---------------------------
目前,对文档的向量解释从一组文档中产生同时出现的单词(彼此之间有K个单词/同义词的距离),因此这些单词具有关系。对吗?
因此,在处理文档时,我们会得到一个单词列表和共现单词示例,这代表了单词使用的共性,由'K'距离(stemrule)
它word2vec帮助我们知道我们应该包括,“痤疮|自然|抢”在我们的新文件的句子。
"因为痛苦痤疮,我会一直对待它自然,这就是为什么我建议你去抓住一本我的新书
然而,不是这个句子应该和另一个包含另一个stemrule的句子有多接近?
所以如果我在句子中使用另一个stemrule:
“这是绝对至关重要的是保持受伤或创伤保护我们行为迅速确保骨头没有转变"
在新文件中,这两个新句子可以在同一段中,也可以相隔很远。
有没有办法知道这种“茎规则的相似性”?所以向量stemrules的使用方式确保了它们与其他stemrules的接近是考虑到stemrules与其他stemrules的距离吗?
因此,我们得到了"分组词干规则"因此,我们生成的新文档更"像原始文档"
或者说,这就是lda2vec所做的吗?
----------------------
"我会考虑用余弦相似度对向量进行聚类"
你能不能教我怎么做,或者再解释一下?
谢谢你的帮助,
把李
-----------------
社区里似乎有很多关于如何将Word2Vec与Twitter数据一起使用的问题。我做了一个快速而肮脏的过程在这里.
现在,如果你想做一些适当的文本挖掘,这意味着这些数据需要转换为文档(所以文本格式)。有相当多的操作符有不同的选项,所以这完全取决于你真正想要/需要做什么,以及你的excel是如何构建的。
德国多特蒙德
德国多特蒙德
德国多特蒙德