
多目标特征选择第4部分:制作更好的机器学习模型


无监督学习的特征选择
在第1部分在本系列中,我们确定特征选择是一个计算困难的问题。然后我们看到进化算法可以解决这个问题在第二部分中.最后,我们讨论了多目标优化提供了额外的见解你的数据和机器学习模型。
还有一件事我们还没有讨论,那就是多目标特征选择。它也可以用于无监督学习。这意味着您现在还可以确定查找集群的最佳特征空间。让我们更详细地讨论一下这个问题,看看我们现在如何解决它。
无监督特征选择与密度问题
在这篇文章中,我们将重点讨论集群问题。下面的所有内容也适用于大多数其他无监督学习技术。
好的,我们现在讨论k均值聚类。该算法的思想是为给定数量的聚类识别质心。这些质心是它们各自集群的数据点的所有特征的平均值。然后我们将所有的数据点分配给这些质心,在一些点被重新分配后,这些质心将被重新计算。此过程在迭代次数达到最大值或集群保持稳定并且没有重新分配点之后停止。
那么我们如何衡量算法分割数据的效果呢?有一种常用的技术可以做到这一点,即Davis-Bouldin索引(或简称:DB索引)。可以用下式计算:

与n作为集群的数量,ci作为簇的质心我,σ我为聚类中所有点的平均距离我到它们的质心,和d (ci, cj)作为星团质心之间的距离我和j.
正如我们所看到的,如果聚类中的点彼此接近,聚类的结果会更好。这当然正是我们想要的,但这也意味着DB索引更喜欢集群密度更高的聚类结果。
但是这种对集群高密度的偏好给特征选择带来了问题。如果我们进行特征选择,我们会减少特征的数量。更少的特征也意味着剩余维度的密度更高。这很直观,因为我们将数据点从高维空间映射到更小的维度,使这些点彼此更接近。
传统的特征选择不能用于聚类。想象一下,我们的数据中有一个特征是纯噪声,但完全是随机的。假设我们抛硬币,正面用0,反面用1。我们想要使用k=2的k-means聚类在我们的数据中找到两个聚类,然后决定使用前向选择来找到这个任务的最佳特征集。它首先尝试只使用一个特征来找到最佳集群。当然,我们上面描述的随机特征将赢得这场竞赛:它将产生两个具有无限密度的集群!一个集群的所有点都在0,另一个集群的所有点都在1,但要记住,这是一个完全随机的特征。因此,只使用这个维度的聚类对于原始问题和数据空间来说是完全没有意义的。
即使在没有伪分类随机特征的情况下,我们也只会选择一个特征。也就是产生k个最密集簇的那个。添加更多的特征只会再次降低密度,所以我们不会去那里。
解决方案:多目标特征选择
多目标优化能帮助解决这个问题吗?让我们做一些实验,看看它是如何工作的。下面的数据集在两个维度上有四个聚类:att1和att2.还有四个额外的随机特性叫做random1,random2等.随机特征使用值在0附近的高斯分布。请注意:数据是归一化的,所以所有数据列的平均值为0,标准差为1。这个过程被称为标准化。
如果你想继续学习,可以在这篇文章的底部找到每个过程的链接。如果只看维度,这是数据集的样子att1和att2:

在这里很容易看到四个自然集群。但是,如果用相同的点颜色绘制相同的数据,情况就会有所不同。下面我们使用维度random1和random2而不是:

正如预期的那样,您再也看不到任何集群,数据点随机地分散在中心周围。在我们开始特征选择之前,让我们在包含所有6个特征的完整数据集上运行k=4的k-means聚类。
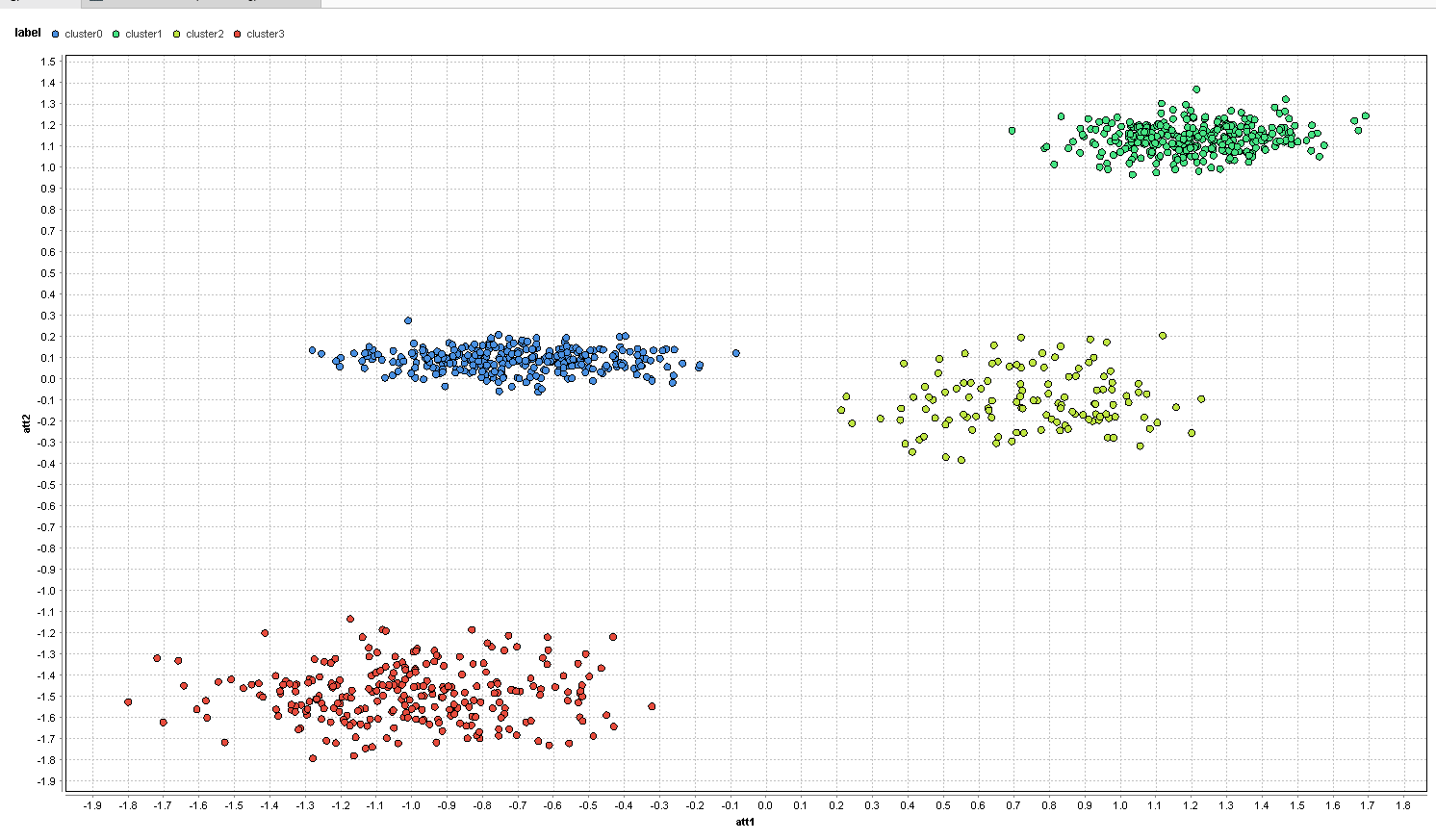
这些聚类现在代表了通过k-means找到的聚类它们并不是完全可怕的。尽管如此,额外的随机属性还是偏离了我们的k-means。在左边,红色和蓝色的星团完全混在一起,一些红色和蓝色的点甚至在右边的星团中。右边的黄色和绿色集群也是如此。
我们可以看到,噪声属性可以使聚类完全没有意义。没有找到所需的群集。由于传统的特征选择没有帮助,让我们看看多目标方法的效果如何。
我们使用与上一篇文章(链接)相同的基本设置。首先,我们检索数据集,然后如上所述对数据进行规范化。然后我们使用一种进化特征选择方案,其中我们使用“非支配排序”作为选择方案。

特征选择运算符内部的差异更大:

我们可以使用k=4来创建聚类,而不是使用10倍交叉验证。第一个性能操作符获取聚类结果并计算DB-Index。第二个运算符计算当前个体使用的特征数量。我们将这个数字作为优化的第二个目标。
{kind=link}
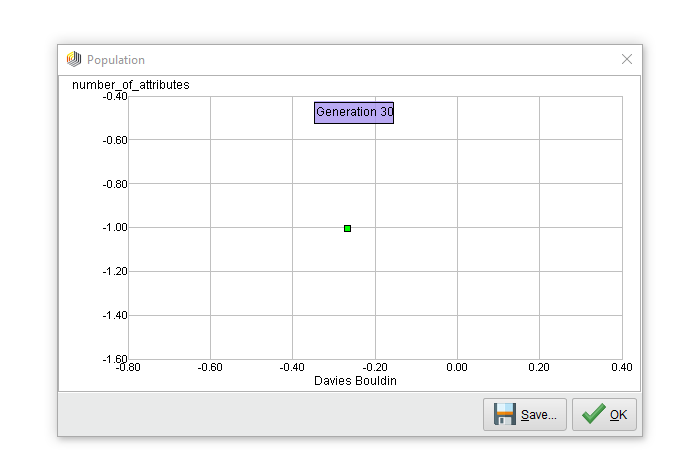
在帕累托前线只有一分吗?当然!任何试图最小化特征数量和优化聚类密度的特征选择方案最终都只会得到一个特征。在12代之后,帕累托锋面塌陷成这个单点,并在接下来的运行中保持这种状态。
选择的特性是att2,这是个不错的选择。事实上,这是直方图,显示了在该维度上发现的四个集群的分布:

红色和绿色的星团很不错。然而,在蓝色和黄色的簇之间有很多重叠。再次查看这篇文章中的第一张图片,并将四个集群只投射到att2上,结果将是相同的。
我们可以同意,我们需要属性att2和att1来获得所需的集群,但是我们最终只得到一个特性。似乎单靠多目标优化并不能解决这个问题。原因是这两个目标并不冲突,所以不会有一个帕累托前线显示所有的权衡。根本就没有什么需要权衡的。
这里有一个想法:如果我们改变特征数量的优化方向会怎样?如果最小化功能的数量并不冲突,为什么我们不引入冲突来最大化功能的数量呢?
这听起来可能很疯狂,但如果我们仔细想想,这是有道理的。聚类的全部意义在于描述您的数据。最好尽可能地保持接近原始数据空间,并且只省略真正的垃圾。如果我们省略太多,那么我们的描述就不再有用了。这就像你在描述一个物体时遗漏了太多的细节。“It has wheels”并不是对“汽车”的错误描述,但它也适用于许多其他东西,比如自行车、摩托车,甚至飞机。但加上“……和四个座位和一个引擎”,就可以更好地描述,而不会添加太多不必要的细节。在我的博士论文中,我们把这个想法称为“信息保存”。
事实上,你只需要在上面的RapidMiner过程中改变一件事。第二个性能作业者有一个创造性的参数,称为“优化方向”。当我们把它从“最小化”改为“最大化”,我们就可以开始了。下面是我们在优化运行结束时得到的帕累托前沿:

看起来好多了,不是吗?我们在这条帕累托曲线上有五个不同的点。对于只使用前两个属性的DB索引和使用3、5或6个特性的其余解决方案有明显的区别。是什么让前两个解特别呢?下面是关于解决方案的详细信息:

首先,我们只使用一个属性得到两次相同的解决方案。我们已经知道,att2是这里的赢家,拥有最好的数据库索引。然而,下一个版本在数据库索引方面只是稍微差一点,并且还添加了“必要”特性att1。从那时起,当我们开始添加随机特性时,DB-Index明显下降。
如果不检查结果集群,就无法对集群集做出最终选择。但现在我们至少可以看看它们是否有意义,并以一种有意义的方式描述我们的数据。在db指数明显下跌之前,从这些领域入手通常是个好主意。这与选择最佳簇数k的已知肘部准则没有什么不同。我们可以在上面的帕累托前图中清楚地看到这种下降的形状。
由于该方法的信息保存特性,它提供了所有相关的信息。你在一次优化运行中就得到了这些信息。最终解决了无监督学习的特征选择问题。
结论
即使在深度学习时代,仍然有很多应用程序比其他模型类型更优越或更受欢迎。此外,在几乎所有情况下,这些模型都受益于通过删除不必要的特征来减少输入数据中的噪声。模型不容易过度拟合,并且变得更简单,这使得它们对小数据变化更健壮。此外,简单性大大提高了模型的可理解性。
进化算法是一种功能强大的特征选择技术。它们不会陷入第一个局部最优,比如正向选择或向后淘汰。这导致了更精确的模型。
一个更好的方法是使用多目标选择技术。这些算法在相同的运行时间内提供完整的Pareto前端解决方案。我们可以自己检查复杂性和准确性之间的权衡(“添加这个额外的功能真的值得吗?”),并且您将获得有关功能交互的额外见解。
最后,这种多目标特征选择方法还有一个优点。我们可以将它用于无监督学习,比如聚类技术。然而,我们需要改变特征数量的优化方向。这在最大化基于密度的集群测量时很容易看到。如果我们同时最小化特征的数量,我们最终只会得到一个属性,但是如果我们最大化属性的数量,就很难找到包含更多特征的密集集群。这将为所有合理数量的特性提供最佳集群。我们还保留了原始信息,这就是聚类的全部内容:找到原始数据中的隐藏部分。
现在我们有了它:未来需要的唯一功能选择解决方案。
RapidMiner流程
你可以在这里下载RapidMiner.然后你可以下载下面的过程,在RapidMiner中自己构建这个机器学习模型。结果将是一个.rmp文件,可以通过“file”->“Import Process”加载到RapidMiner中。请注意,您需要运行前三个进程来创建将由其他进程使用的数据集。请根据您的设置调整所有进程的存储和检索操作符参数中的存储路径。
作者:@IngoRMRapidMiner创始人兼总裁


评论
如果它仍然可用,有人可以张贴一个链接到“第4部分”的示例过程吗?文章中提到了它,我可能忽略了一些明显的东西,但我没有看到它。
谢谢,
诺埃尔
Ingo