
术语频率和TF-IDF:它们是如何计算的?

术语频率和TF-IDF:它们是如何计算的?
你是否像我一样,长时间使用“流程文件”,但从来没有真正理解这些数字是什么?或者可能只是一个喜欢矢量分析的数学极客?无论哪种方式,放松一下,而我带你通过一个循序渐进的例子,究竟是如何术语出现,术语频率(TF),以及术语频率-逆文档频率(TF- idf)在RapidMiner工作…
设置示例
我们将从一个非常简单的例子开始:一个语料库中的两个简短文档。文档1说“这是一篇关于数据挖掘和文本挖掘的报告”,文档2说“这是一篇关于视频分析的文章”。我将结合这两个文档,并通过“过程文档”使用Tokenization, Transform Cases和Filter Stopwords(英文)来运行它们:
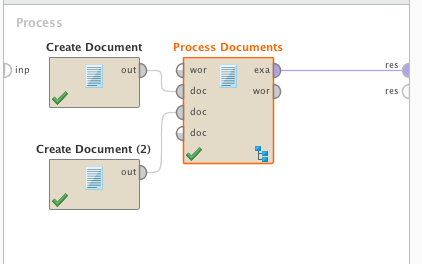
主要过程

在“过程文件”中

没有词向量的结果
词出现
这是您可以做的最基本的单词标记向量化。它只是计算单词记号在每个文档中的出现次数,以创建一个“术语出现词向量”:
 2个文档样本语料库的术语出现
2个文档样本语料库的术语出现
二进制项的出现
这也是相当直接的。唯一的区别是选项只有0和1。因此,您将看到唯一的更改是在文档1中,RapidMiner将“2”更改为“1”,简单地表示至少出现了一次令牌“mining”。
 2个文档样本语料库的二进制项出现
2个文档样本语料库的二进制项出现
词的频率
这就是事情变得有趣的地方。在最基本的级别上,Term Frequency (TF)就是每个单词标记的出现次数与文档中单词标记总数的比率。首先,我使用Process Documents中的Extract Token Number操作符来获取每个文档中的单词令牌总数:
 在Process Documents操作符中使用“Extract Token Number”获取语料库中每个文档的Token计数的结果
在Process Documents操作符中使用“Extract Token Number”获取语料库中每个文档的Token计数的结果
现在术语频率应该是有意义的:
 2个文档样本语料库的术语频率
2个文档样本语料库的术语频率
但你可能会注意到,当你在“矢量创建”参数中选择“术语频率”时,这不是RapidMiner给你的:
 RapidMiner对包含2个文档的样本语料库的Term frequency的结果
RapidMiner对包含2个文档的样本语料库的Term frequency的结果
为什么?因为RapidMiner中显示的术语频率词向量是归一化向量。这和单位向量归一化你们可能在物理课上见过。在粗笔画中,(欧几里得)向量的范数是它的长度或大小。如果你有一个1x2向量,你可以通过简单的勾股定理找到范数。对于像上面每个文档一样的1x6向量,您可以在6维空间中使用勾股定理。因此,第一个文档项频率向量的范数为:
SQRT ((0) ^ 2 + (0.200) ^ 2 + (0.400) ^ 2 + (0.200) ^ 2 + (0.200) ^ 2 + (0) ^ 2] = 0.529
第二个文档项的频率向量为:
√6 [(0.333)^ 2 + (0)^ 2 + (0)^ 2 + (0)^ 2 + (0.333)^ 2 + (0.333)^ 2]= 0.577
为了平等地查看所有文档,我们希望所有文档向量具有相同的长度。因此,我们将每个文档项频率向量除以其各自的范数,得到一个“文档项频率单位向量”——也称为a归一化项频率向量。
如果我们将每个文档项频率向量中的每个项频率除以它的范数:
0 / 0.529 = 0 0.200 / 0.529 = 0.378 0.400 / 0.529 = 0.756 0.200 / 0.529 = 0.378 ....
0.333 / 0.577 = 0.577 0 / 0.577 = 0 0 / 0.577 = 0 0 0 / 0.577 = 0 ....
我们将得到每个文档的归一化项频率向量——就像RapidMiner显示的那样。![]()
RapidMiner对包含2个文档的样本语料库的Term frequency的结果
逆文档频率(IDF)
好吧,但为什么要超越tf呢?好吧tf的问题在于它们只查看单个文档中相对于其他单词标记的单词标记,而不是相对于整个语料库的单词标记。通常在文本挖掘中,您希望在大量文档上训练ML模型,而不是一个文档。因此,在许多文档中找到特别强大的单词标记远比单独的每个文档重要得多。
但是什么是强的呢?这就像普通机器学习中的加权属性一样;能够区分一个文档与另一个文档的单词标记应该比其他不提供这种洞察力的单词标记的权重更大,即我们对单词标记的权重进行加权独特性而不是它受欢迎程度。
假设你有一个图书馆,希望训练一个模型,根据“有动物”和“没有动物”对书籍进行分类。显然,像“老虎”、“大象”和“熊”这样的词标记比“如果”、“或”和“因为”这样的词标记重要得多。所以我们称这个独特的强度因子为an逆文档频率发生的次数越少,应该越强烈。
让我们看看我们的语料库。我们有两个文档,总共有六个唯一的单词令牌:分析、数据、挖掘、报告、文本和视频。注意,单词令牌“text”出现在两个文档中——它的预测强度不应该像每个文档中唯一的其他单词令牌那么大。我们可以做这样简单的事情:
分析:1/2 = 1/2
数据:1/2 = 1/2
挖掘:2个文档中的1个= 1/2
报告:2份文件中的1份= 1/2
文本:2个文件中的2个= 2/2
视频:1/2 = 1/2
但我们希望“text”更强,所以让我们使用指数:
分析:1/2 = e^(1/2) = 1.649
数据:1/2 = e^(1/2) = 1.649
挖掘:2个文档中的1个= e^(1/2) = 1.649
报告:1 out of 2 documents = e^(1/2) = 1.649
文本:2个文件中的2个= e^(2/2) = 2.718
1/2 = e^(1/2) = 1.649
但这不是一个好主意。想象一下,如果你有100个文档,其中只有一个有“视频”;其他的在100份文件中有99份,因此重要性要低得多;你会希望“视频”对他们有很大的影响。这一点都不好用。
分析:99 / 100 = e^(99 / 100) = 2.691
数据:100个文档中的99个= e^(99 / 100) = 2.691
挖掘:100个文档中的99个= e^(99 / 100) = 2.691
报告:100个文件中的99个= e^(99 / 100) = 2.691
文本:100个文档中的99个= e^(99 / 100) = 2.691
1 / 100 = e^(1 / 100) = 1.01
但是如果你把它翻过来,发现ln对于倒数,它就像你所期望的那样:
分析:99 / 100 = ln (100 / 99) = ln 1.01 = 0.01
数据:99 / 100文档= ln (100 / 99) = ln 1.01 = 0.01
挖掘:100个文档中的99个= ln (100 / 99) = ln 1.01 = 0.01
报告:99 / 100文件= ln (100 / 99) = ln 1.01 = 0.01
文本:100个文档中的99个= ln (100 / 99) = ln 1.01 = 0.01
视频:1 / 100 = ln (100 / 1) = ln 100 = 4.605
在这里单词代币“视频”的权重大约是其他单词代币的461倍。这说得通。
现在让我们看一下我们最初的一个IDF向量的例子。正如您所看到的,单词标记“text”的强度比其他具有相同强度(或重量)的单词要小得多,这是应该的。
分析:1 / 2 = ln (2 / 1) = 0.693
数据:1 of 2个文档= ln (2 / 1) = 0.693
挖掘:2个文档中的1个= ln (2 / 1) = 0.693
报告:1 out of 2个文件= ln (2 / 1) = 0.693
文本:2个文档中的2个= ln (2 / 2) = 0
视频:1 / 2 = ln (2 / 1) = 0.693
∴
IDF向量= (0.693 0.693 0.693 0.693 0 0.693)
Term Frequency - Inverse Document Frequency (TF-IDF)
那么现在让我们通过将每个项频率向量乘以逆文档频率向量(表示为对角矩阵)来将它们组合在一起:
文档1 TF-IDF:
(0 0.2 0.4 0.2 0.2 0) x (0.693 0 0 0 0 0 0 0 0)
(0 0.693 0 0 0 0 0)
(0 0 0.693 0 0 0)
(0 0 0 0 0 0)
(0 0 0 0 0.693 0)
(0 0 0 0 0 0.693)
= (0.138 0.277 0.138 0 0)
文档2 TF-IDF:
(0.333 0 0 0 0.333 0.333) x (0.693 0 0 0 0 0)
(0 0.693 0 0 0 0 0)
(0 0 0.693 0 0 0)
(0 0 0 0 0 0)
(0 0 0 0 0.693 0)
(0 0 0 0 0 0.693)
= (0.231 0 0 0 0 0.231)
现在剩下的就是对TF- idf向量进行归一化就像我们对TF所做的那样
SQRT ((0) ^ 2 + (0.138) ^ 2 + (0.277) ^ 2 + (0.138) ^ 2 + (0) (0) ^ ^ 2 + 2] = 0.340
√6 [(0.231)^ 2 + (0)^ 2 + (0)^ 2 + (0)^ 2 + (0)^ 2 + (0.231)^ 2]= 0.327
文件1:0 / 0.340 = 0 0.138 / 0.340 = 0.408 0.277 / 0.340 = 0.816 0.138 / 0.340 = 0.408 ....
文件2:0.231 / 0.327 = 0.707 0 / 0.327 = 0 0 / 0.327 = 0 0 0 / 0.327 = 0 ....
这正是RapidMiner为TF-IDF提供的!
 包含2个文档的样本语料库的TF-IDF的RapidMiner结果
包含2个文档的样本语料库的TF-IDF的RapidMiner结果









评论
非常非常有用,斯科特。我明白了。谢谢。
假设我有一个包含2500个文档的语料库(本质上是数据集中的一个文本列),我对它进行td-idf分析,并获得所有行(文本)中所有项的逆频率向量。
然后我添加了一个新的文本行,并希望将这一行与其他2500行进行“评分”,以确定它们与每一行的相似程度。我如何设置RM来做这个分析?td-idf是否有方法进行分析并获得分数,以便可以看到我的测试行与其他“文本”(或行)的“相似”程度?
Andres Fortino
嗨,安德烈斯。
你想看每一行的相似性吗?我只是使用数据到相似性操作符…