
交叉验证及其在RM Studio中的输出
在RM Studio中,我们得到了很多关于Cross Validation操作符究竟是如何工作的问题,以及那些“exa”、“mod”和“tes”输出产生了什么。因此,最好在一篇知识库文章中对此进行深入解释。所以我走了…
什么是交叉验证?
交叉验证是一种用于在相对较小的数据集上找到对数学模型性能的真实估计的方法。它在数据的子集上构建一系列模型,并在剩余的数据上测试每个模型,以确定一个平均性能指标的模型,而不是一个性能指标一个模型的。
分割验证是一个简单得多的过程,你只需将数据分成“训练”集和“测试”集,它非常适用于非常大的数据集。但它的致命弱点是它假设测试集是整个数据集的代表性样本。对于大型数据集来说,这可能是正确的,但数据集越小,这种可能性就越小。交叉验证是如何工作的?
交叉验证的工作原理是首先将数据集划分为n个分区,然后每次构建n个唯一的模型(每次迭代称为“折叠”)。对于每次迭代,使用n-1个分区和第n个分区创建一个模型。模型本身无关紧要;保留的是模型性能。重复使用不同的分区作为保留集,直到每个分区都被使用。
在计算n个性能之后,我们计算交叉验证期间建立的所有n个模型的平均性能(及其标准差)。
最后,我们用整个数据集建立了一个真实的模型,并显示了计算出的平均性能。
交叉验证的非常简单的例子
让我们通过一个非常简单的例子来了解它是如何工作的。这是一个数据集,其中我们有一个自变量(x)和一个因变量(y)。目标是使用交叉验证产生这些数据的最佳线性回归模型。y值是随机生成的。

在这个例子中,我们将使用线性抽样,5倍交叉验证,和RSME作为我们的绩效指标:
- 线性抽样-我们将按数据集提供给我们的顺序拉出保留集
- 五重交叉验证-我们将进行五次迭代,以使用五个保留集找到五种表演
- RSME-每个保留集的预测值与实际值的均方根误差

折叠2
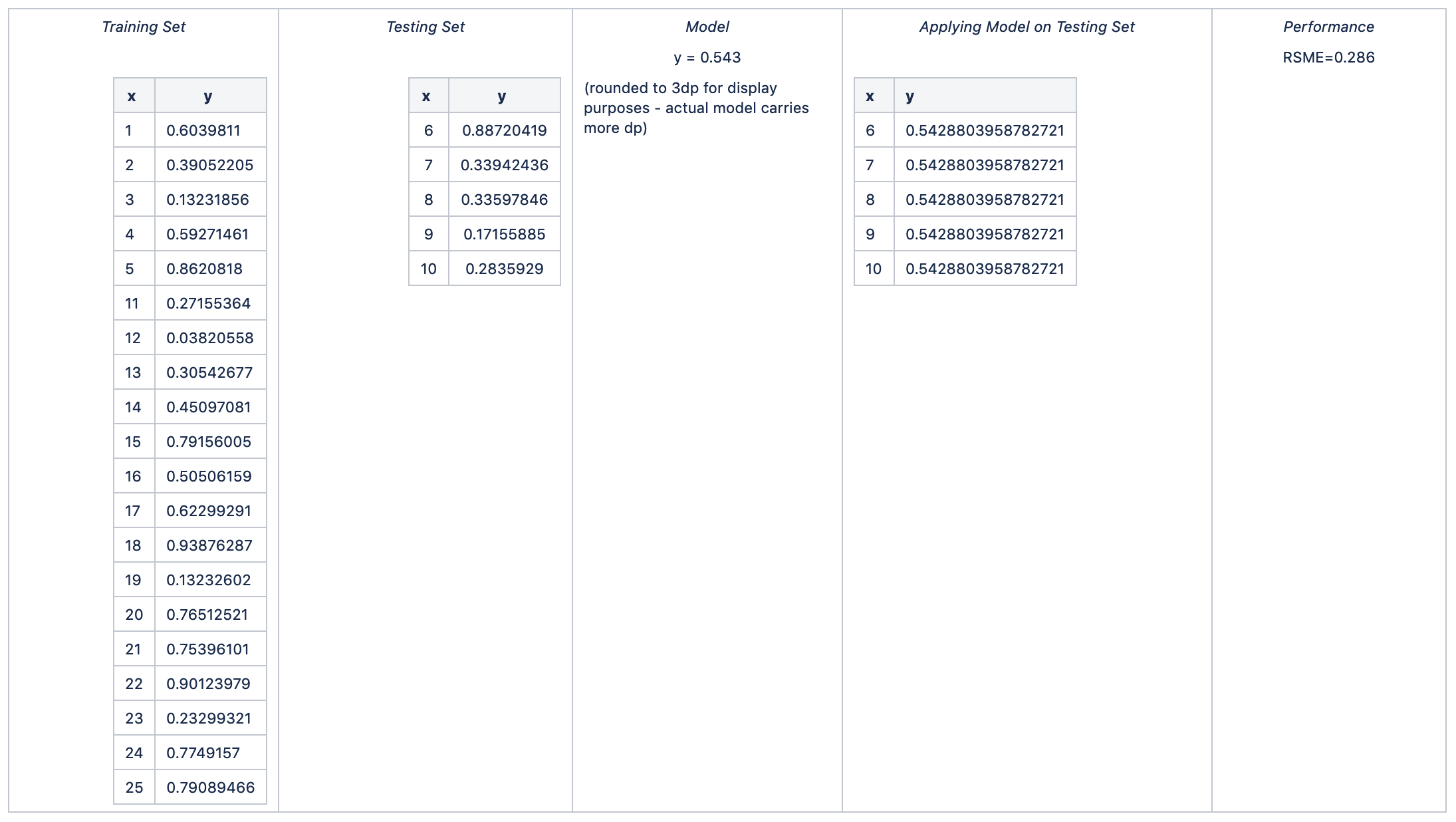
3折

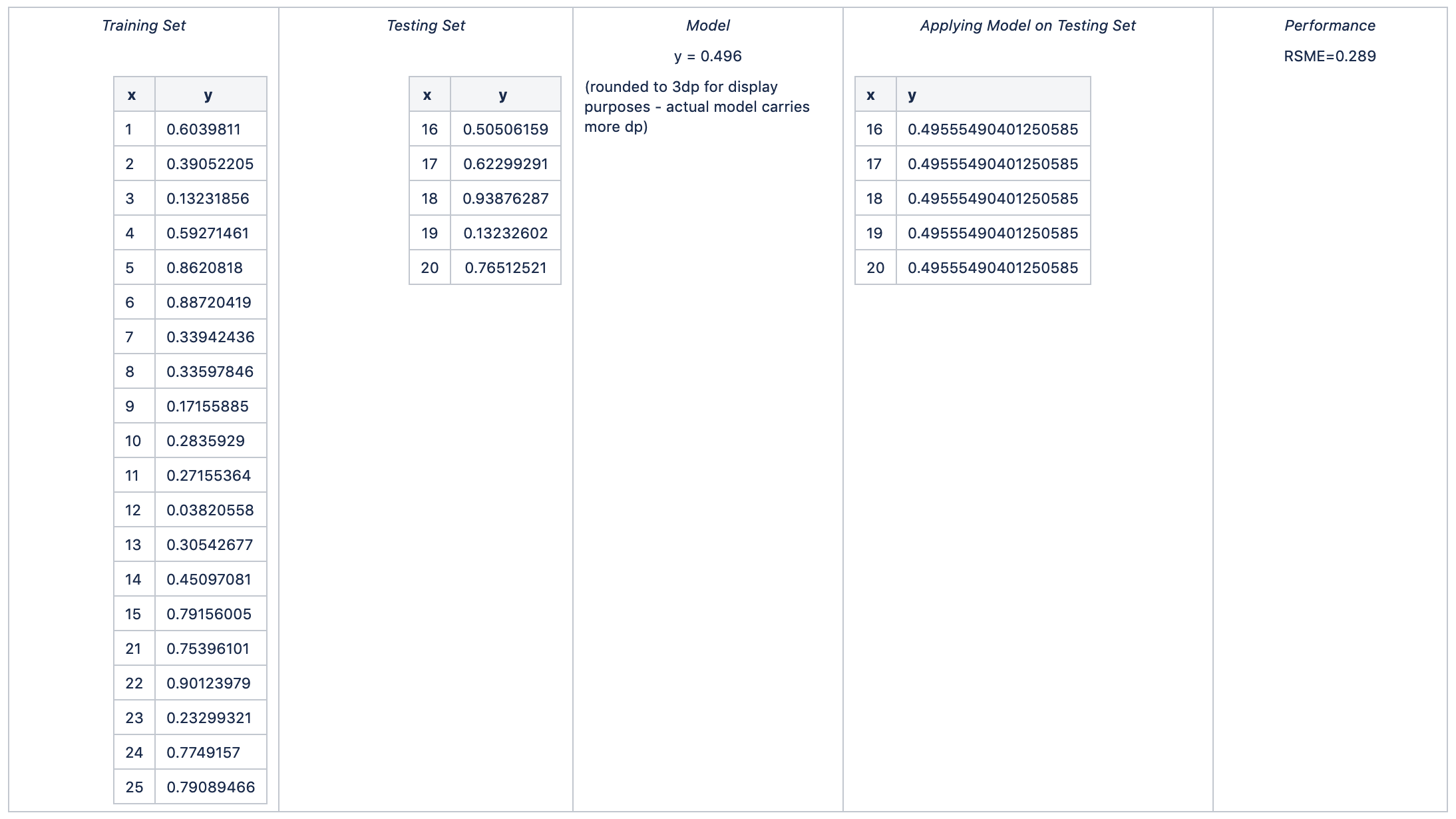
4折
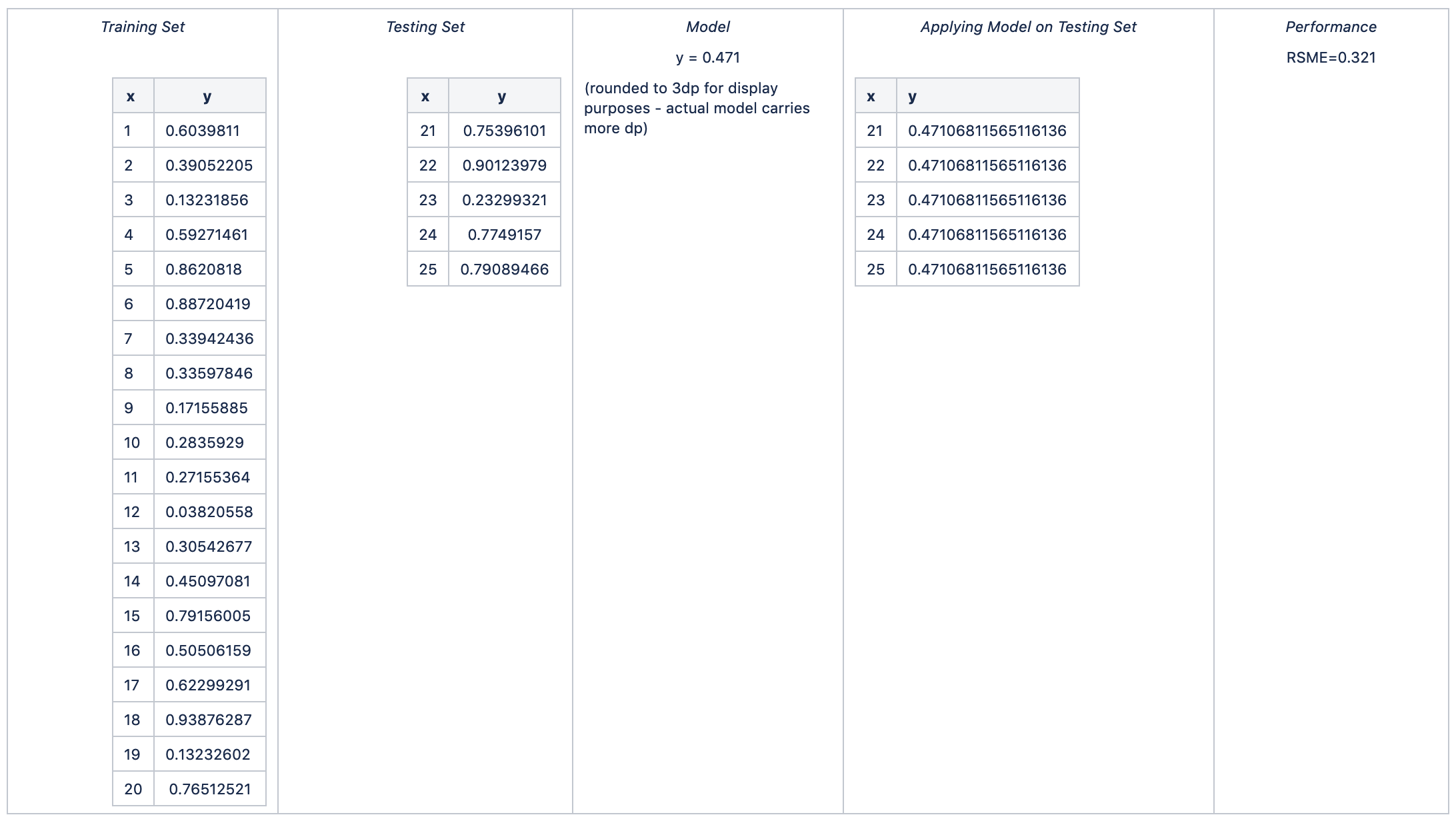
因此:
平均RSME = avg (0.347, 0.286, 0.306, 0.289, 0.321) = 0.310
RSME的标准差= stdev (0.347, 0.286, 0.306, 0.289, 0.321) = 0.025
表示此性能指标的模型不是上面所示的模型;它是在整个数据集上产生的一个新模型。有时这被认为是“n+1”次迭代。
计算实际模型
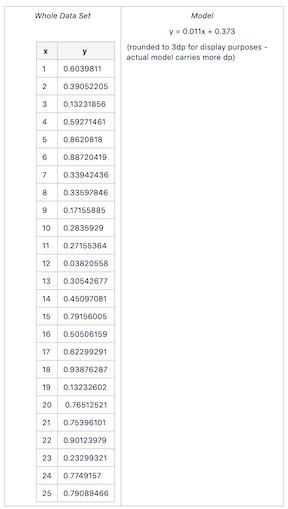
在RapidMiner Studio交叉验证操作符的输出是什么?
好了,现在我们可以回答这个问题了!它们如下:
- 国防部-建立在整个数据集上的实际数学模型(参见上面的最后一步)。通常只显示相关系数或等价物。
- 穰-原始的ExampleSet (data)。这是一个简单的传递。
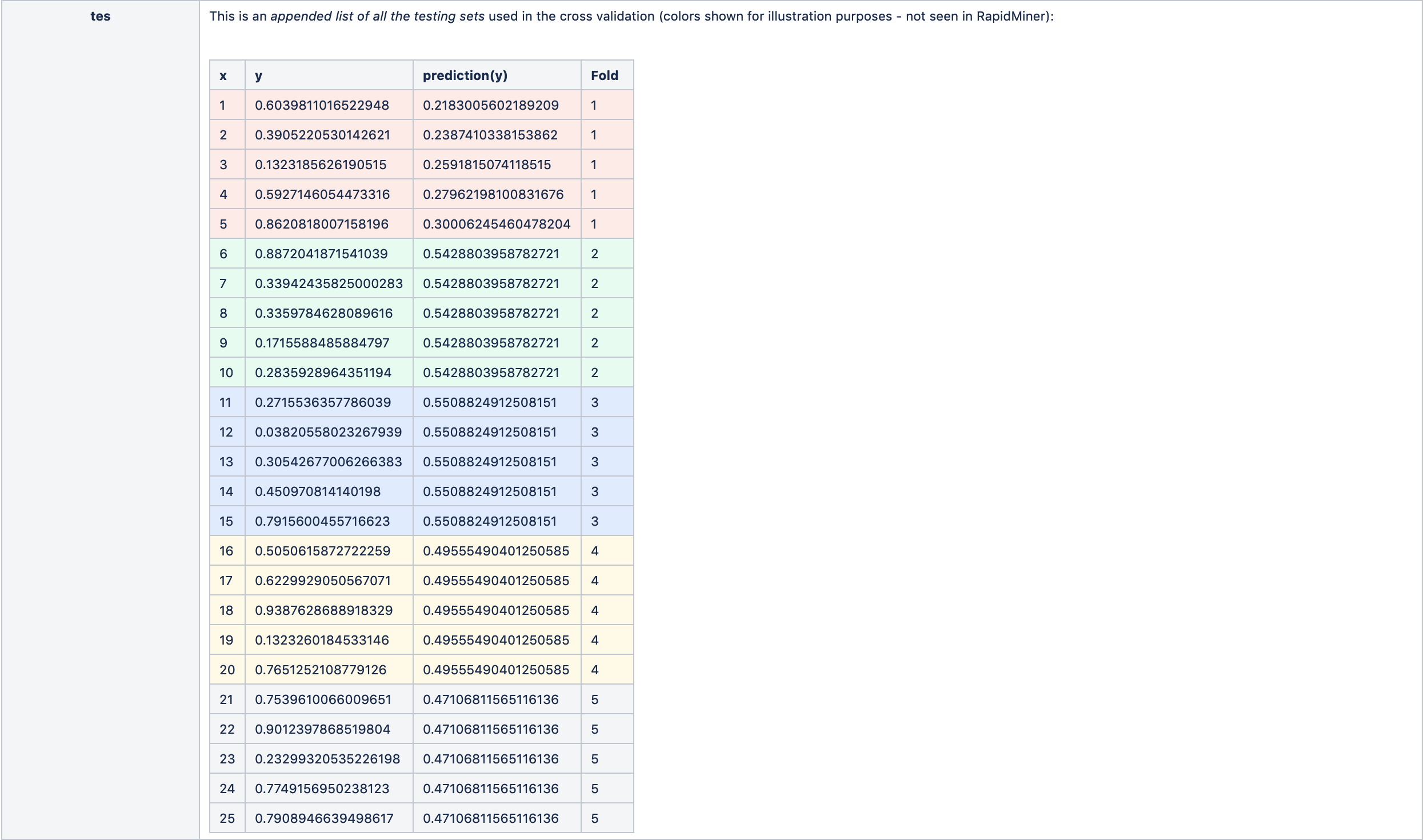
- 测试工程师-测试ExampleSet。注意,这不是最终模型在数据集上的应用;相反,它在一个附加列表中显示来自n次交叉验证的所有保留测试集。
- 每= n次交叉验证的平均性能
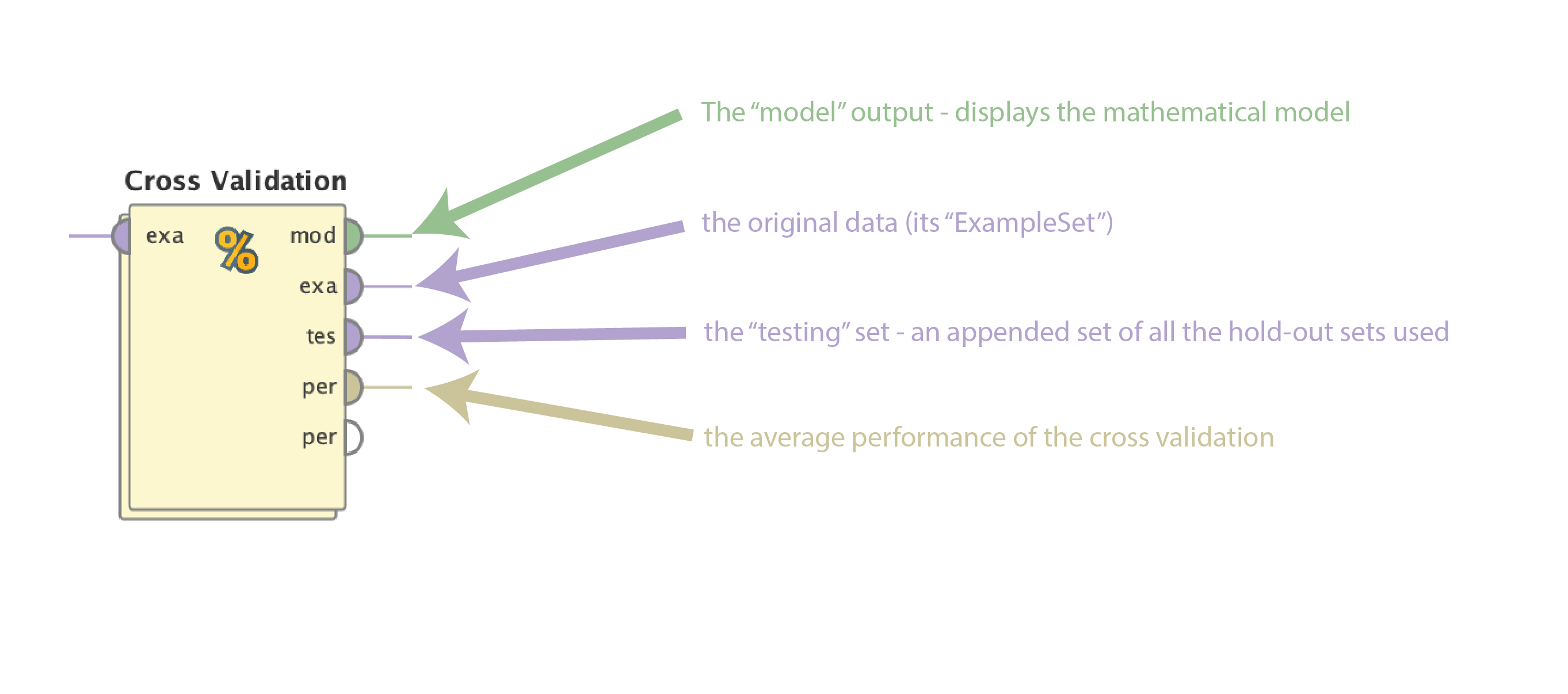
对于我们的例子,它们如下:

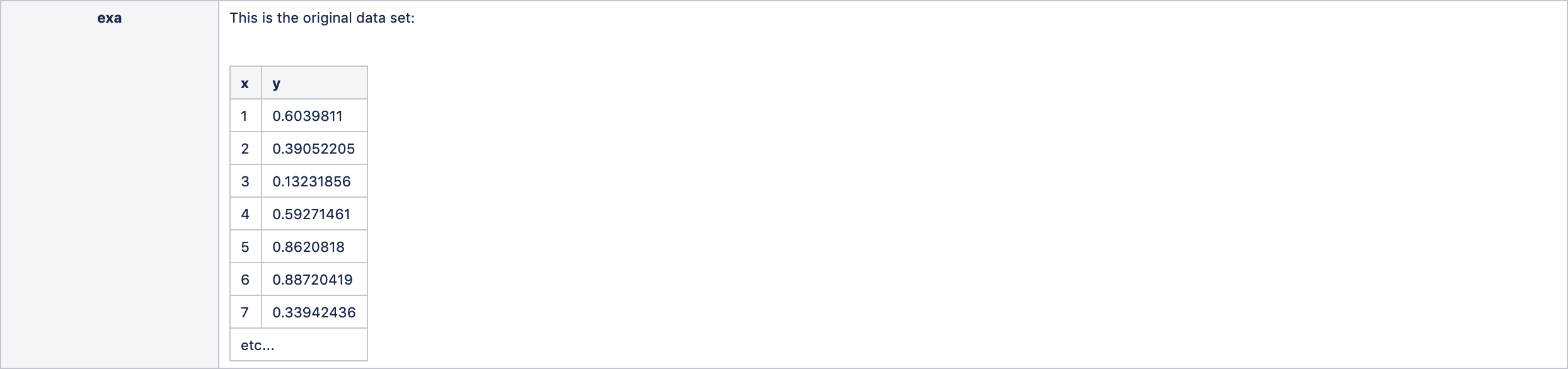

我们为什么要费这么大的劲呢?
我要插入几段创始人的文章@IngoRM在这里:交叉验证与模型构建完全无关。这是一种常见的估算方案(不是计算!)(微妙但重要的区别)给定模型对未知数据的处理效果。因此,我们在最后提供一个模型(出于方便的原因)这一事实可能会使您得出这样的结论:它实际上也是关于模型构建的——但事实并非如此。
好的,这就是为什么这种验证只是对给定模型的估计的近似值:通常你想使用尽可能多的数据,因为标记的数据是昂贵的,在大多数情况下,学习曲线告诉你,更多的数据导致更好的模型。你在完整的数据集上建立模型因为你希望这是你能得到的最好的模型。辉煌!这是上面给出的模型。你现在可以在实践中使用这个模型,希望得到最好的结果。或者你想提前知道这个模型在实际使用之前是否真的很好。我更喜欢后一种方法;-)
所以现在(实际上是在你建立了所有数据的模型之后)你当然也有兴趣学习这个模型在不可见数据上的实际效果。你能做的最接近的估计是所谓的“留一验证”,你使用除了1个数据点以外的所有数据点进行训练,剩下的一个数据点用于测试。对所有数据点重复这个过程。这样,你构建的模型是“最接近”你真正感兴趣的模型(因为只缺少一个例子),但不幸的是,这种方法对于大多数现实世界的场景是不可行的,因为你需要为一个有1,000,000个例子的数据集构建1,000,000个模型。
这就是交叉验证进入阶段的地方。它只是一个更可行的近似,这已经只是一个开始的估计(因为我们甚至在LOO的情况下省略了一个例子)。但这总比什么都没有好。重要的是:它是对原始模型(建立在所有数据之上)的性能估计,而不是模型选择的工具。如果有的话,您可能会误用交叉验证作为工具,例如选择,但我现在不会深入讨论这个问题。
更值得思考的是:你可能知道如何平均10个线性回归模型——我们如何处理10个具有不同优化网络结构的神经网络?还是10个不同的决策树?如何取平均值?总的来说,这个问题无论如何也解决不了。
事实是,这些都不是好主意;您应该做正确的事情,即在尽可能多的数据上构建一个模型,并使用交叉验证来估计该模型在新数据上的表现。
希望这能帮助到一些人。谢谢你!@yyhuang和@IngoRM谢谢你的帮助!
斯科特











