
解释预测:对支持和反对正确预测的属性进行排序

你好,
大多数特征选择技术将为我们提供支持预测目标标签的最佳预测器。这些主要依赖于预测器和输出标签(类)之间的相关性。
大多数特征选择技术将为我们提供支持预测目标标签的最佳预测器。这些主要依赖于预测器和输出标签(类)之间的相关性。
这个过程的一个限制是属性从一个模型到另一个模型的变化的重要性。这主要取决于其他属性存在时属性强度的变化,也取决于模型统计背景。
我们如何知道这些变量中哪一个在预测特定算法的正确标签方面表现更好呢?
在RapidMiner中,有一个“解释预测”操作符,它提供统计和可视化观察,以帮助理解每个属性在预测中的作用。该操作符使用局部相关值指定每个属性(Predictor)角色,以预测与数据中单个样本相关的特定值。这个角色可以支持预测,也可以与预测相矛盾。这些都是漂亮的视觉与不同的颜色变化的红色和绿色。红色表示与预测相矛盾的属性,绿色表示支持预测的属性。
我们如何知道这些变量中哪一个在预测特定算法的正确标签方面表现更好呢?
在RapidMiner中,有一个“解释预测”操作符,它提供统计和可视化观察,以帮助理解每个属性在预测中的作用。该操作符使用局部相关值指定每个属性(Predictor)角色,以预测与数据中单个样本相关的特定值。这个角色可以支持预测,也可以与预测相矛盾。这些都是漂亮的视觉与不同的颜色变化的红色和绿色。红色表示与预测相矛盾的属性,绿色表示支持预测的属性。
如何知道哪些属性支持和反对正确的预测,反之亦然?
如前所述,你在可视化中看到的颜色代码属于正确和不正确的预测。如果您有兴趣找到支持和反对正确预测的属性,该怎么办?这就是我写这篇文章的动机。在预测建模中,只有少数模型可以提供变量的全局重要性。在复杂算法的情况下,很难找到具有全局意义的属性。但是,在“解释预测”操作符的帮助下,我们可以为支持和反对预测的预测生成排名。我将在下面的流程示例中解释这一点。
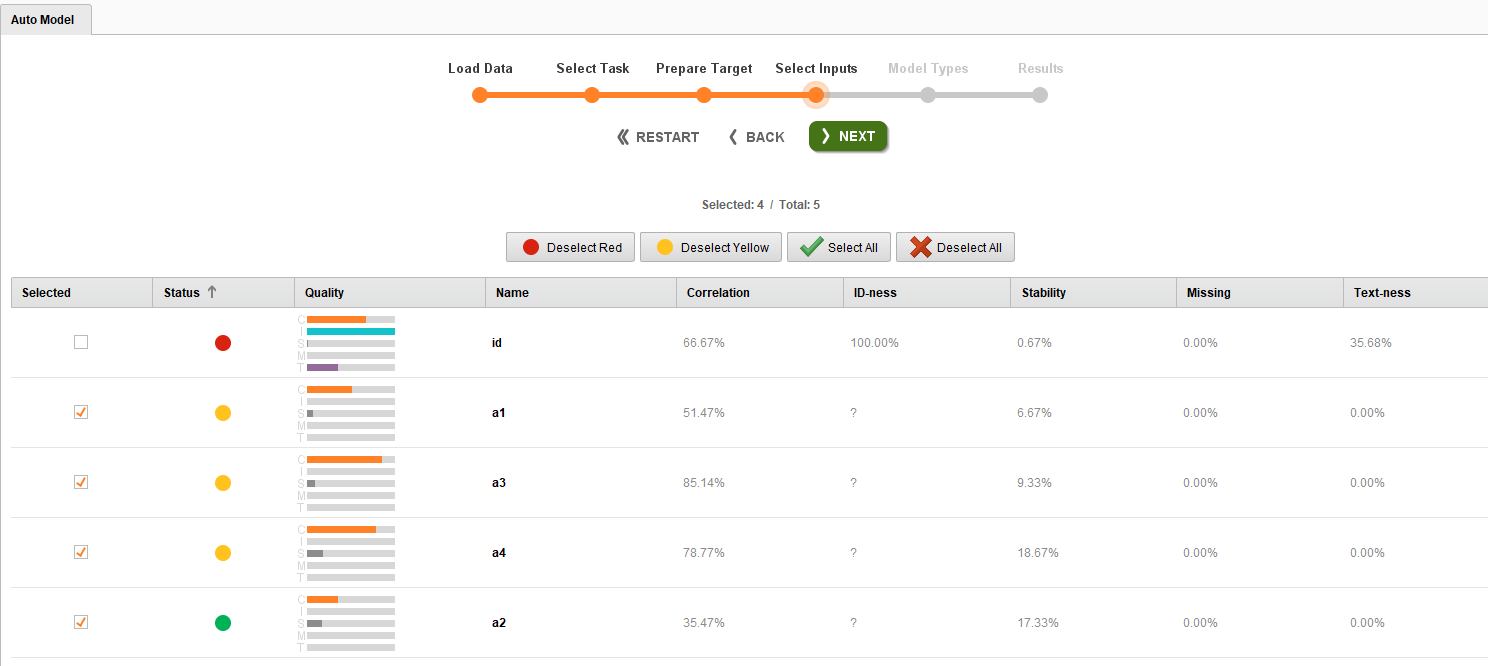
下面附上的流程文件是基于IRIS数据集的。我们在这里看到的问题是基于四个属性(a1到a4)对不同的花进行分类。我尝试用自动模型来寻找属性的重要性。自动模型提供了基于以下四个因素的重要属性(https://docs.www.turtlecreekpls.com/8.1/studio/auto-model/).现在,我首先观察了汽车模型中属性的重要性,发现a2是最好的预测器,正如你可以在下面的图中看到的那样,它用绿色表示。其他三个属性用黄色表示,这意味着它们对模型预测的影响中等。为了测试这一点,我运行了包含和删除这三个属性的模型(5次交叉验证)。
下面附上的流程文件是基于IRIS数据集的。我们在这里看到的问题是基于四个属性(a1到a4)对不同的花进行分类。我尝试用自动模型来寻找属性的重要性。自动模型提供了基于以下四个因素的重要属性(https://docs.www.turtlecreekpls.com/8.1/studio/auto-model/).现在,我首先观察了汽车模型中属性的重要性,发现a2是最好的预测器,正如你可以在下面的图中看到的那样,它用绿色表示。其他三个属性用黄色表示,这意味着它们对模型预测的影响中等。为了测试这一点,我运行了包含和删除这三个属性的模型(5次交叉验证)。
有趣的是,与没有这四种属性相比,有这四种属性的模型表现得非常好。kappa值从0.3增加到0.9。因此,这意味着对于这个数据集,我们最好包括所有四个属性。现在,下一个任务是试图了解哪些属性在预测正确标签方面表现良好。为此,我们使用解释预测操作符以及一些常规操作符来对性能进行排名(提供这种排名方法)。
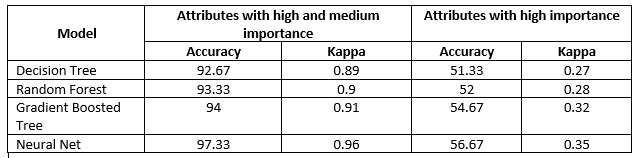
我比较了四种分类模型(决策树、兰登森林、梯度增强树和神经网络)的性能,并确定了每个模型中属性对正确预测的重要性。从下图中,可以观察到每个属性的重要性随着算法的不同而变化。正值表示支持属性,负值表示与正确预测相关的矛盾属性。这些属性是根据它们的重要性排序的。

现在,为了观察只有支持属性的影响,我删除了上面确定的与正确预测相矛盾的属性,并再次运行模型。从结果中,我观察到决策树和梯度提升了树的性能。随机森林性能无明显差异,但神经网络性能下降。在机器学习中,我们尝试不同的疯狂的事情,因为没有既定的规则来获得更好的预测。
非常感谢您的评论和反馈。
谢谢
现在,为了观察只有支持属性的影响,我删除了上面确定的与正确预测相矛盾的属性,并再次运行模型。从结果中,我观察到决策树和梯度提升了树的性能。随机森林性能无明显差异,但神经网络性能下降。在机器学习中,我们尝试不同的疯狂的事情,因为没有既定的规则来获得更好的预测。
非常感谢您的评论和反馈。
谢谢





9
评论
彩色状态气泡为数据列提供了质量指示器。
Ingo
如果对此有任何误解,请纠正我。
Varun
https://www.varunmandalapu.com/
是安全的。遵循预防措施,保持社交距离
Varun
https://www.varunmandalapu.com/
是安全的。遵循预防措施,保持社交距离
我喜欢RM,因为它很容易让初学者进入大数据分析的世界,他们实际上可以使用RM进行一些复杂的项目。然而,有时由于缺少一些常用的函数而限制了它的使用。我想说功能的重要性就是其中之一。
你在找什么样的特征重要性算法?
Varun
https://www.varunmandalapu.com/
是安全的。遵循预防措施,保持社交距离
这是人们用来产生一个学习者的思想,它预测了另一个学习者的不确定性,不是吗?
德国多特蒙德