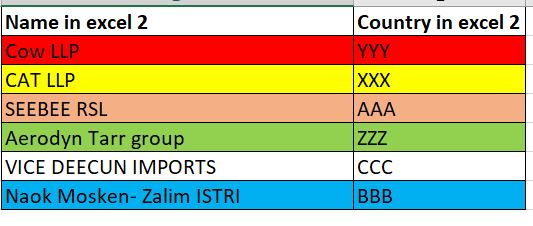
我有2个优秀。两者都有公司名称和国家数据。但是公司名称是相似的,并不相同。因此,使用国家数据(是相同的),我必须匹配公司名称,并在一个excel文件中显示最终匹配的数据。我还附上了两个excel中的数据示例。我用颜色编码了它,以便它们可以被理解为类似的公司名称(Cat INC = Cat LLP)。我创建了一个使用像replace这样的操作符的模型(有很多手工工作,比如输入可替换的值)。而且,真正的数据文件包含1000行的数据。因此,如果有人能提出一种模型类型,可以比较和匹配两个文件之间的数据,这将是有帮助的。


 Jayanthan12
成员职位:3.
Jayanthan12
成员职位:3.
答案
你有工具箱扩展安装尝试新的“模糊匹配”操作符?它将使用流行的Levenshtein距离或任何其他变化距离度量来合并两个模糊匹配的表。它将显示您想要的几个候选匹配。
您可以在模糊匹配之后应用一个过滤器,以确保县名完全相同。
示例流程在这里
欢呼,
YY
我有2个优秀。两者都有公司和国家名称。但是公司名称是相似的,并不相同。我必须匹配公司名称(即使名称中的一个单词是匹配的,例如:猫公司而且猫LLP)应该匹配),并将最终匹配的数据显示在一个excel文件中,如下(3)所示。我还附上了两个excel(1和2)的数据示例。我用颜色编码了它,以便它们可以被理解为类似的公司名称(Cat INC = Cat LLP)。而且,真正的数据文件包含1000行的数据。因此,如果有人能提出一种模型类型,可以比较和匹配两个文件之间的数据,这将是有帮助的。
你可以从“读取Excel”中加载数据并尝试一下
输出是这样的
HTH !
YY