您正在查看的是RapidMiner Radoop 9.2 -版本文档查看最新版本
在RapidMiner Studio中配置RapidMiner Radoop连接
配置RapidMiner Studio中的RapidMiner Radoop与一个或多个Hadoop集群之间的连接管理Radoop连接而且连接设置对话框。控件访问这些对话框连接菜单,Hadoop数据视图,或设计视图。在配置和保存连接项之后,您可以在部署之前对它们进行测试。该测试验证到集群的连接,并验证连接设置是否符合RapidMiner Radoop的要求先决条件.
有三种方法可以创建Radoop连接。我们强烈推荐第一种。
如果您可以访问集群管理器软件(Apache Ambari或Cloudera manager),我们强烈建议使用
 从集群管理器导入选项.这种方法是最简单的。
从集群管理器导入选项.这种方法是最简单的。如果您不使用或没有权限访问集群管理器,但可以请求客户端配置文件,然后使用
 导入Hadoop配置文件选项.
导入Hadoop配置文件选项.否则,你总是可以选择
 手动添加连接.最后一个选项还允许您导入某人与您共享的Radoop连接点击在编辑XML…按钮,一旦连接设置对话框出现了。
手动添加连接.最后一个选项还允许您导入某人与您共享的Radoop连接点击在编辑XML…按钮,一旦连接设置对话框出现了。
注意:配置RapidMiner Radoop时,必须提供主节点的内部域名或IP地址(即主节点知道自己的域名或IP地址)。看到网络设置概述有关如何确保您的数据免受未经授权的访问的详细信息。
RapidMiner Radoop基本连接配置
安装RapidMiner Radoop后,可以创建连接。
重新启动RapidMiner Studio,使其能够识别RapidMiner Radoop扩展。一旦它重新启动,您将看到一个新的
 管理Radoop连接选项中的连接菜单:
管理Radoop连接选项中的连接菜单:
-
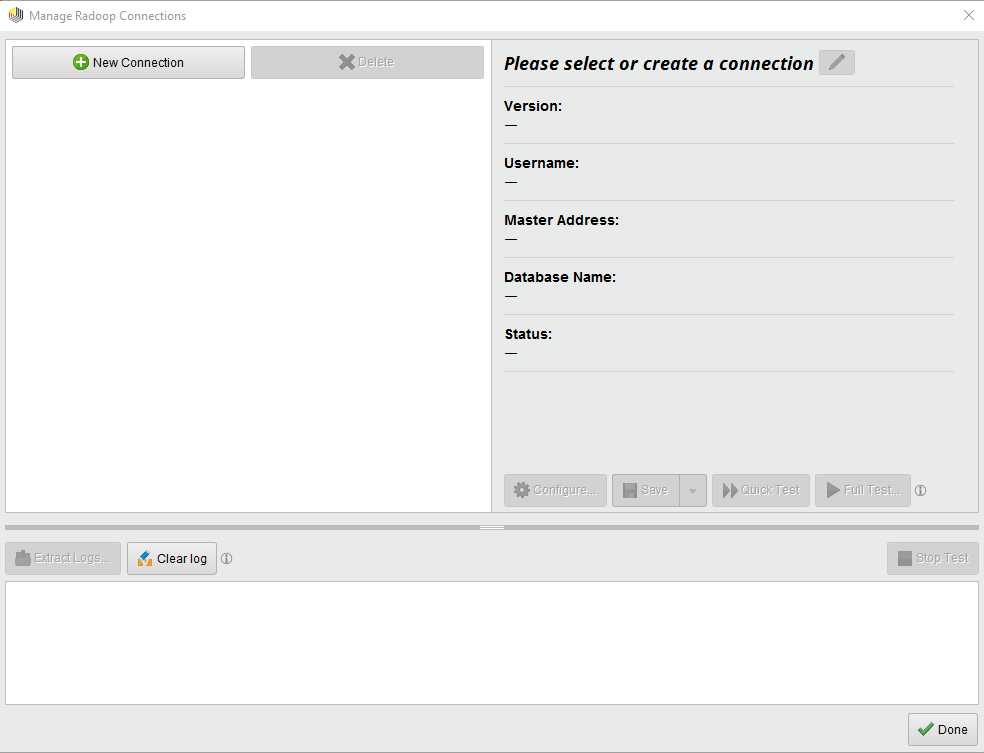
有关此对话框的详细信息,请参见管理Radoop连接下面的部分。
点击
 新连接按钮并选择手动添加连接:
新连接按钮并选择手动添加连接: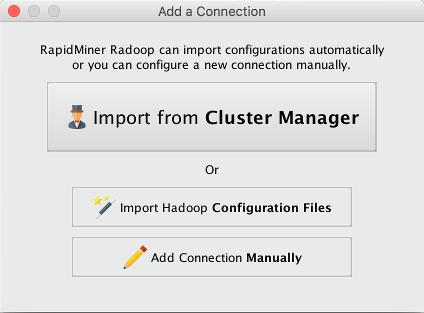
如果希望通过导入客户端配置文件或使用集群管理服务来创建连接,请阅读导入Hadoop配置部分。
属性中的连接属性连接设置对话框。
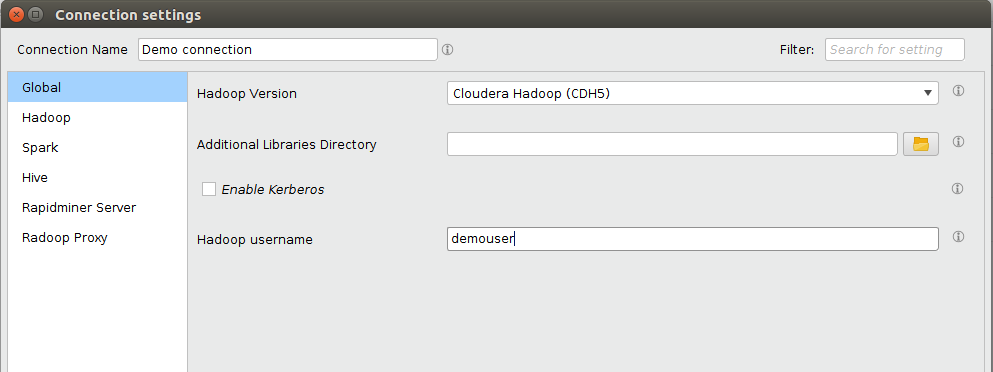
您可以在对话框的顶部提供连接的名称。可以通过选择左侧适当的选项卡来配置其他设置。完成下面列出的所需连接字段。请注意,DNS和反向DNS应该适用于所有指定的地址,因此客户端机器必须能够访问集群的网络名称解析系统,或者能够在本地解析地址。
选项卡 场 描述 全球 Hadoop版本 为此连接定义Hadoop版本类型的发行版。 Hadoop NameNode地址 运行NameNode服务的节点的地址(通常是主机名)。 Hadoop 资源管理器地址 运行资源管理器服务的节点的地址(通常是主机名)。 蜂巢 Hive服务器地址 Hive Server或Impala Server所在节点的地址(通常为主机名)。 火花 火花版本 集群上可用的Spark版本。 火花 程序集Jar Location / Spark Archive(或libs)路径 Spark Assembly Jar文件/ Spark Jar文件的HDFS位置或本地路径(在所有集群节点上)。 有关详细信息,请参见高级连接设置下面的部分。
点击
 好吧创建连接条目。
好吧创建连接条目。点击
 保存将条目添加到可用连接中。
保存将条目添加到可用连接中。测试连接RapidMiner Radoop和Hadoop集群之间。如果有必要,在Hadoop管理员的帮助下,设置高级设置基于特定分发说明.




您的连接设置保存在一个名为radoop_connections.xml在你的.RapidMiner目录中。
导入连接
对于更复杂的集群,手动配置连接可能很麻烦。在这种情况下,建议使用连接导入特性之一。有两种选择:您可以使用集群的客户端配置文件创建连接,或者为集群的管理服务(Cloudera Manager或Ambari)提供URL和凭据。
您可以通过从客户端配置文件设置其参数来创建Radoop连接。要这样做,请选择![]() 导入Hadoop配置文件选项。在下面的对话框中设置文件的位置:
导入Hadoop配置文件选项。在下面的对话框中设置文件的位置:
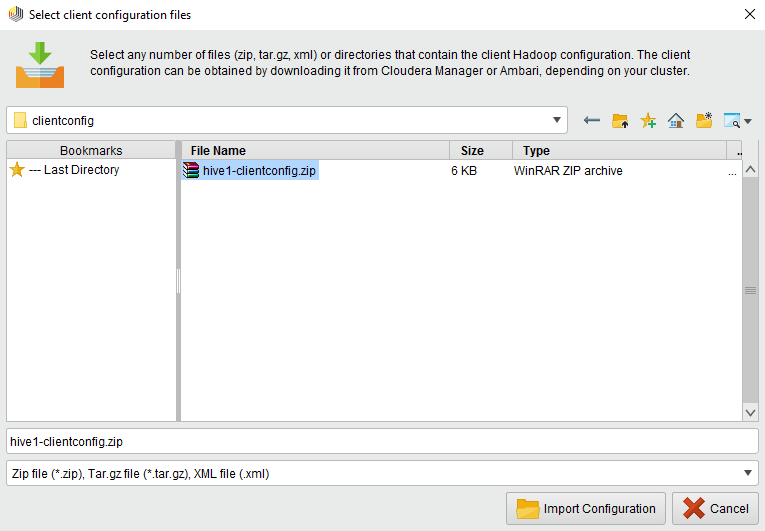
您可以选择一个或多个文件夹或压缩文件(例如邮政编码或tar.gz),包含配置XML文档,或者您可以简单地导入单个xml文件。通过使用分发者的文件,您可以很容易地获得这些文件Hadoop管理工具.点击![]() 导入配置然后等待,直到弹出窗口显示导入过程的结果:
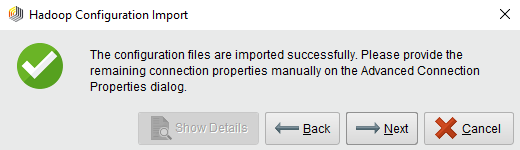
导入配置然后等待,直到弹出窗口显示导入过程的结果:
 成功:您可以继续下一步。
成功:您可以继续下一步。 警告:有些字段将会丢失,这些字段可以在下一步中提供。
警告:有些字段将会丢失,这些字段可以在下一步中提供。 显示详细信息按钮将问题通知给您。
显示详细信息按钮将问题通知给您。 失败:你该走了
失败:你该走了 回来并选择适当的文件。
回来并选择适当的文件。
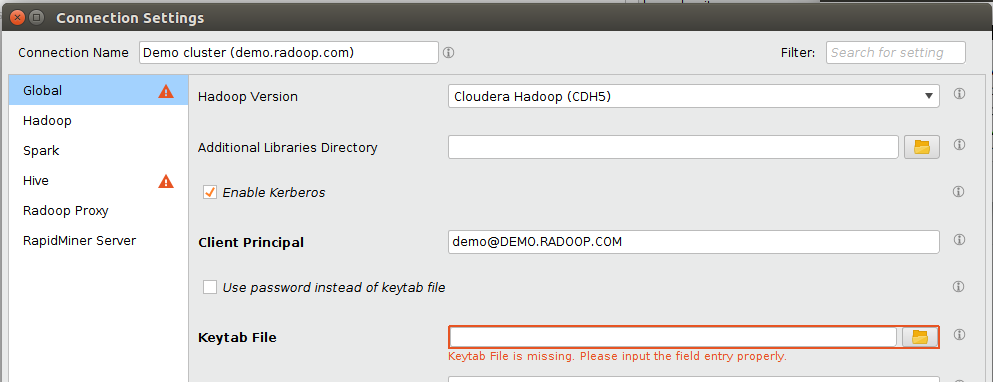
点击![]() 下一个会带你到连接设置对话框,在这里您可以找到所有可以自动导入的属性。一些必需的字段可能仍然缺失。编辑器用红色边框和错误消息突出显示它们。如果选项卡包含缺值的字段,则用错误符号标记它。
下一个会带你到连接设置对话框,在这里您可以找到所有可以自动导入的属性。一些必需的字段可能仍然缺失。编辑器用红色边框和错误消息突出显示它们。如果选项卡包含缺值的字段,则用错误符号标记它。
您可以通过为集群的管理服务提供URL和凭据来创建连接。在本例中,选择![]() 从集群管理器导入选项,以获得以下对话框:
从集群管理器导入选项,以获得以下对话框:
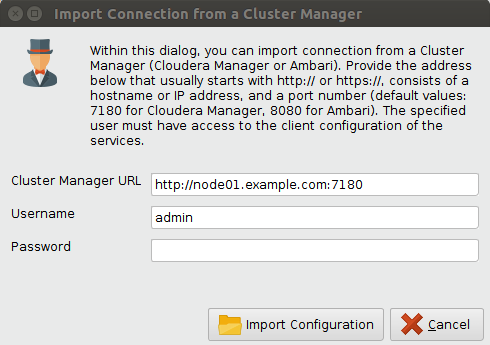
需要填写以下字段:
- 集群管理器URL:集群管理服务的URL。对于类似HDP的连接(HDP, HDInsight, IOP, IBM等),这通常是Apache Ambari,它通常默认在端口8080上运行(HDInsight除外,通常不需要提供端口)。对于CDH连接,这是Cloudera Manager,默认情况下在端口7180上运行。请注意协议前缀(通常是http, https)。如果缺少协议,将自动使用“http://”。
- 用户名:集群管理器的用户名。请注意,用户需要拥有客户端配置的特权。只读权限足以检索大多数连接属性。虽然不需要使用管理用户,但可以检索其他必须手动提供的进一步设置。
- 密码:提供的集群管理器用户密码。
填写完字段后,单击![]() 导入配置启动导入过程。如果集群管理器管理多个集群,将弹出以下输入对话框。选择要连接的集群的名称。
导入配置启动导入过程。如果集群管理器管理多个集群,将弹出以下输入对话框。选择要连接的集群的名称。
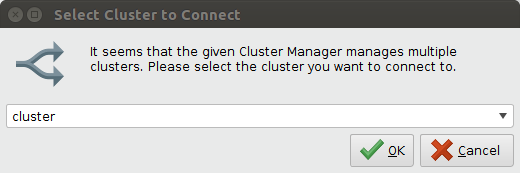
连接导入可以有两个结果:
- 成功:您可以继续下一步。
- 失败:你该走了回来修复URL或凭证单击。可以看到详细的错误显示详细信息按钮。
- 如果失败是由于不受信任的证书,将通知用户并显示证书详细信息,并提供信任证书的选项,并继续从集群管理器导入。
成功导入连接后,将连接设置弹出对话框。在这里,您可以更改连接的名称,并手动完成连接配置。
- 缺少值的必填字段将用红色边框和错误消息突出显示。包含缺值字段的选项卡将用错误符号标记。
- 可能需要更改默认值的字段将用橙色边框突出显示,并且选项卡将用警告标志标记。请注意,如果您使用Apache Ambari作为集群管理器,Hadoop版本将自动设置为HDP。例如,对于IBM和ODP发行版,需要手动更改Hadoop版本。
在从导入创建连接时,可能会检测到重复的属性。
如果检测到重复的属性,则与前一个属性值的冲突消除如下所示。
解除冲突是基于属性的起源,并按以下降序解决:
-纱线产地
- core-site origin
-其他产地按加工顺序排列
同源内的优先级,遵循顺序读取顺序。
如果属性值被替换,将提供一个INFO级别日志,说明键、值/原点是什么,以及现在应用了什么值/原点。
管理Radoop连接窗口
管理Radoop连接窗口显示您已经配置的连接,并允许您编辑它们,或创建和测试新连接:
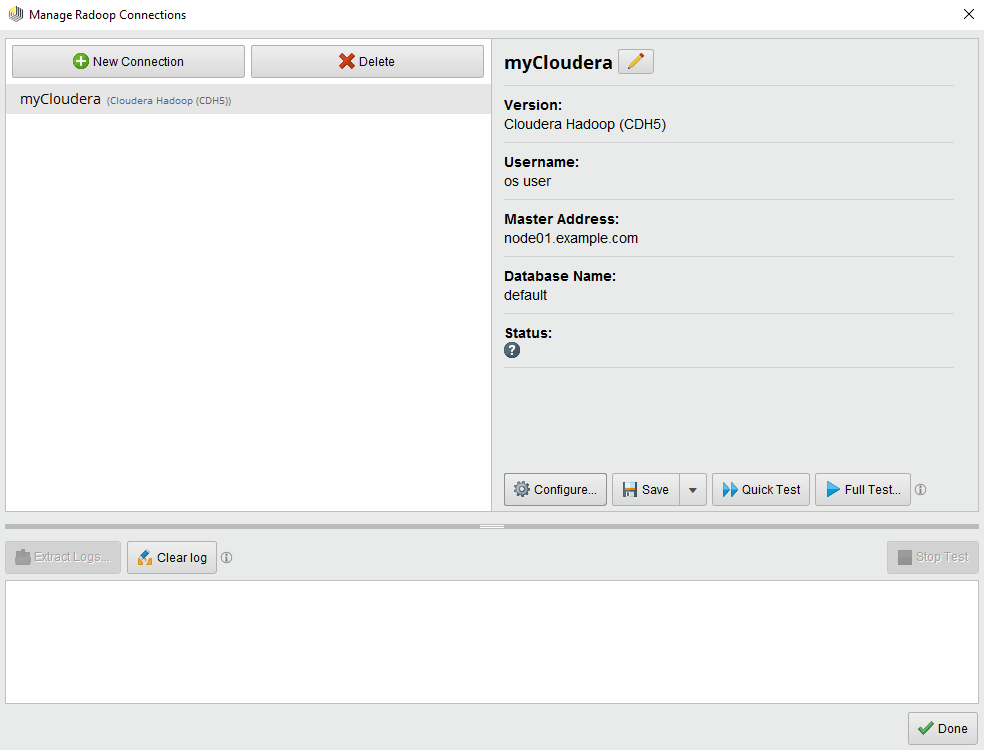
这个窗口由3个面板组成。左上面板列出了所有已知的连接项。对于每个条目,一个或多个图标可能会显示一些额外的信息,即:
 此连接已配置Spark
此连接已配置Spark 连接使用Impala作为查询引擎
连接使用Impala作为查询引擎 连接到安全集群
连接到安全集群
当前所选连接的基本属性聚集在右侧面板上。在选定的连接上,还有一些按钮执行一些可用的操作:
 配置…:打开“连接设置”对话框,您可以在其中配置连接属性。检查高级连接设置部分了解更多详细信息。
配置…:打开“连接设置”对话框,您可以在其中配置连接属性。检查高级连接设置部分了解更多详细信息。- 保存:保存当前显示的连接。
 另存为…:保存当前显示连接的副本。用于保存稍微修改过的连接,同时保留原始条目。
另存为…:保存当前显示连接的副本。用于保存稍微修改过的连接,同时保留原始条目。 快速测试:在当前显示的连接上运行快速测试。
快速测试:在当前显示的连接上运行快速测试。 完整的测试……:在此连接上运行完全集成测试。有关连接测试的更多信息,请参见测试RapidMiner Radoop连接部分。
完整的测试……:在此连接上运行完全集成测试。有关连接测试的更多信息,请参见测试RapidMiner Radoop连接部分。- 重命名操作:重命名当前连接。请注意,所有连接名称都应该是唯一的。
下面板显示正在运行的测试的日志。在这个面板上还可以执行一些操作:
 提取日志……:此操作将创建一个捆绑的zip文件,其中包含您最近与radoop相关的活动的所有相关日志。看到相关的部分欲知详情。
提取日志……:此操作将创建一个捆绑的zip文件,其中包含您最近与radoop相关的活动的所有相关日志。看到相关的部分欲知详情。 清除日志:清除连接日志字段。
清除日志:清除连接日志字段。 停止测试:“停止测试”动作将停止当前正在运行的测试执行(请参阅测试RapidMiner Radoop连接部分)。
停止测试:“停止测试”动作将停止当前正在运行的测试执行(请参阅测试RapidMiner Radoop连接部分)。
测试RapidMiner Radoop集群连接
RapidMiner Radoop的内置测试功能有助于在故障开始之前进行故障排除。
基本连接测试
单击![]() 快速测试按钮。管理Radoop连接窗口测试到集群的连接。通过对集群上不同组件(api)的一系列简单测试,测试验证集群是否正在运行,RapidMiner Radoop客户端是否可以访问它。控件,可以随时停止测试
快速测试按钮。管理Radoop连接窗口测试到集群的连接。通过对集群上不同组件(api)的一系列简单测试,测试验证集群是否正在运行,RapidMiner Radoop客户端是否可以访问它。控件,可以随时停止测试![]() 停止测试按钮。
停止测试按钮。
全连接测试
测试成功后,通过单击。运行完整的测试(可能需要几分钟)![]() 完整的测试……按钮。控件可以自定义完整的连接测试
完整的测试……按钮。控件可以自定义完整的连接测试![]() 自定义…按钮。在此面板中,您可以启用或禁用测试、更改超时以及启用或禁用测试后的清理。关闭后,这些值将重置为默认值管理Radoop连接窗口。点击
自定义…按钮。在此面板中,您可以启用或禁用测试、更改超时以及启用或禁用测试后的清理。关闭后,这些值将重置为默认值管理Radoop连接窗口。点击![]() 运行开始测试。
运行开始测试。
完整测试在集群上启动多个作业和应用程序,然后检查结果。通过成功和广泛地练习RapidMiner Radoop与集群的交互,您可以对RapidMiner Radoop流程设计和执行充满信心。
在首次创建RapidMiner Radoop配置时,除了测试连接外,还可以使用完整的测试如果您在进程执行中出现错误或在集群中发生更改。完整测试结果的输出可以帮助确定问题的根本原因,从而更容易进行故障排除。单击,可以随时停止完整测试![]() 停止测试按钮。停止当前的测试过程可能需要一些时间。
停止测试按钮。停止当前的测试过程可能需要一些时间。
注意:当您打开包含RapidMiner的进程时,集群连接初始测试也会在后台自动启动Radoop巢操作符(由RapidMiner Studio屏幕右下角的状态栏指示)。
高级连接设置
您可以使用连接设置对话框编辑连接参数。例如,您可以使用键值对更改Hadoop和Hive的端口号或定义任意参数。在没有事先咨询组织的IT管理员之前,不要修改连接设置。打开连接设置对话框,单击![]() 配置…按钮。管理Radoop连接窗口。
配置…按钮。管理Radoop连接窗口。
请注意:显示的字段取决于所选择的选项(例如所选择的Hadoop版本)。另外,根据基本设置中的Hadoop版本选择预填充一些字段。如果字段为大胆的在窗口中,这是必需的。
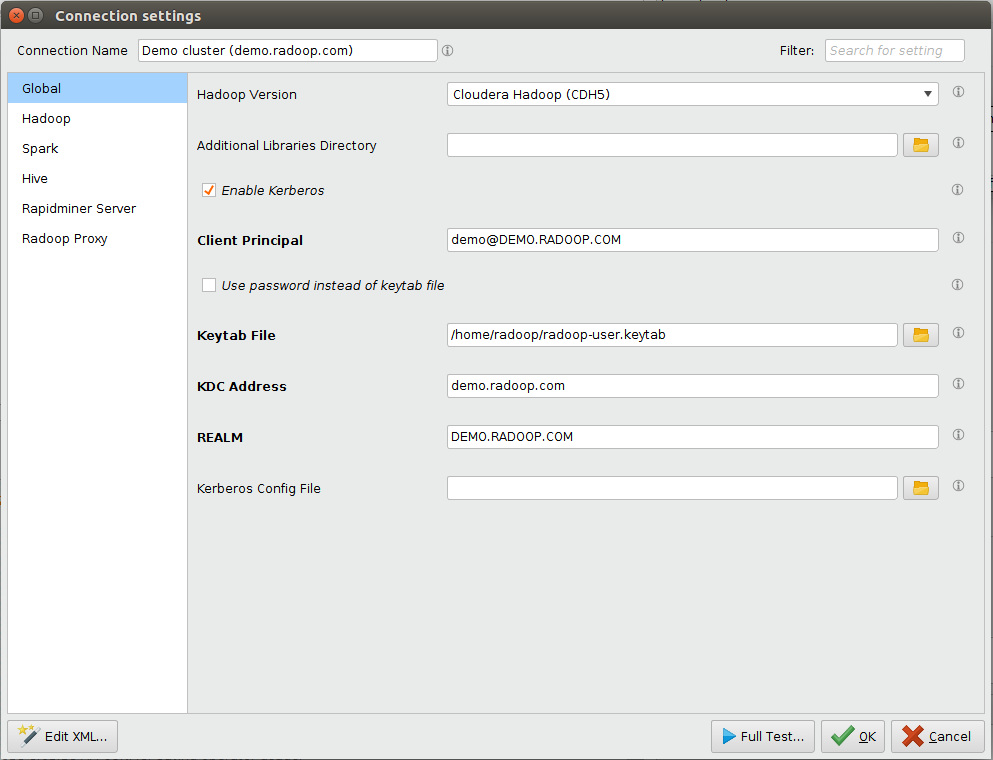
的连接设置对话框有多个选项卡。下表描述了每个选项卡中的字段。有关与您的环境相关的高级配置详细信息,请参见特定分发说明.
全球
| 场 | 描述 |
|---|---|
| Hadoop版本 | 为此连接定义Hadoop版本类型的发行版。 |
| 附加图书馆目录 | 客户端上需要连接到集群的任何附加库(JAR文件)(可选,仅针对专业用户)。 |
| 启用Kerberos | 选中此框以连接到由Kerberos保护的Hadoop集群。 |
| 客户端主要 | 仅在启用Kerberos安全性并禁用服务器模拟的情况下.用户访问Hadoop的主体。格式为primary[/ |
| 使用密码代替keytab文件 | 仅在启用Kerberos安全的情况下.选中此框以使用密码而不是keytab文件进行身份验证。 |
| KeyTab文件 | 客户端机器上用户keytab文件的路径。输入或浏览到文件位置。 |
| 密码 | 仅在启用Kerberos安全并勾选“使用密码而不是keytab文件”选项时.可用于连接到安全集群的Kerberos密码。RapidMiner Radoop使用密码。在radoop_connections.xml中加密密码的密钥文件。 |
| KDC地址 | 仅在启用Kerberos安全的情况下.Kerberos密钥分发中心的地址。例如:kdc.www.turtlecreekpls.com。 |
| 领域 | 仅在启用Kerberos安全的情况下.Kerberos领域。通常是大写字母的域名。例如:RAPIDMINER.COM。 |
| Kerberos配置文件 | 仅在启用Kerberos安全的情况下.为了避免运行RapidMiner的机器与Hadoop集群之间的配置差异,最好提供Kerberos配置文件(通常是krb5.conf或krb5.ini)。从安全管理员处获取此文件。输入或浏览到文件位置。 |
| 启用MapR安全性 | 只有选择了一些MapR Hadoop版本.选中此框以连接到MapR Security保护的Hadoop集群。 |
| MapR集群 | 只有选择了一些MapR Hadoop版本.要连接到的MapR集群。所有MapR连接必须在MapR Home指向的MapR客户端中配置。 |
| Hadoop的用户名 | Hadoop用户名。在大多数情况下,用户必须对集群具有适当的权限。对于新连接,默认为操作系统用户。 |
Hadoop
| 场 | 描述 |
|---|---|
| NameNode地址 | 运行NameNode服务的节点的地址(通常是主机名)。(需要一个有效的网络名称解析系统。) |
| NameNode港口 | NameNode服务端口。 |
| 资源管理器地址 | 运行资源管理器服务的节点的地址(通常是主机名)。 |
| 资源管理器端口 | 资源管理器服务的端口。 |
| JobHistory服务器地址 | 运行作业历史记录服务器服务的节点的地址(通常是主机名)。 |
| JobHistory服务器端口 | 作业历史记录服务器服务的端口。 |
| 从Hive中检索服务主体 | 仅在启用Kerberos安全的情况下.如果选中,RapidMiner Radoop将自动从Hive中检索所有其他服务主体,以便于配置。只有在访问其他服务有问题时才禁用此设置。 |
| NameNode主要 | 仅在启用Kerberos安全性并禁用Hive主体检索的情况下.NameNode服务主体。可以使用_HOST关键字作为实例。例如:神经网络/ _HOST@RAPIDMINER.COM |
| 资源管理主体 | 仅在启用Kerberos安全性并禁用Hive主体检索的情况下.ResourceManager服务的主体。可以使用_HOST关键字作为实例。例如:rm / _HOST@RAPIDMINER.COM |
| JobHistory Server主体 | 仅在启用Kerberos安全性并禁用Hive主体检索的情况下.JobHistoryServer服务的主体。可以使用_HOST关键字作为实例。例如:jhs / _HOST@RAPIDMINER.COM |
| Hadoop高级参数 | Key-value属性用于自定义Hadoop连接和Radoop的Yarn/MapReduce作业。有些连接需要某些高级参数。有关详细信息,请参见特定分发说明. |
火花
| 场 | 描述 |
|---|---|
| 火花版本 | 集群上可用的Spark版本。有关使用的更多信息火花操作符,请参见配置火花部分。 |
| 程序集Jar Location / Spark Archive(或libs)路径 | Spark Assembly Jar文件/ Spark Jar文件的HDFS位置或本地路径(在所有集群节点上)。 |
| Spark资源分配策略 | Spark任务的资源分配策略。默认-动态资源分配从8.1.1和静态、启发式配置在8.1.0中-通常适用。查看更多Spark策略信息. |
| 资源分配% | 为Spark作业分配的集群资源的百分比。乐鱼体育安装该字段仅当静态、启发式配置为Spark资源分配策略。 |
| 使用自定义PySpark存档 | 如果您想提供自己的PySpark存档,请选中此框。 |
| 自定义PySpark归档路径 | 只有当使用自定义PySpark存档选项已启用。用作PySpark作业提交的PySpark库的存档集。看到配置自定义PySpark/SparkR档案的说明. |
| 使用自定义SparkR存档 | 如果您想提供自己的SparkR存档,请选中此框。 |
| 自定义SparkR存档路径 | 只有当使用自定义SparkR存档选项已启用。存档用作SparkR作业提交的SparkR库。用作PySpark作业提交的PySpark库的存档集。看到配置自定义PySpark/SparkR档案的说明. |
| Spark高级参数 | 自定义RapidMiner Radoop的Spark作业的键值属性。看到Spark配置说明. |
蜂巢
| 场 | 描述 |
|---|---|
| 蜂巢版 | 选择合适的数据仓库系统——HiveServer2 (Hive 0.13或更新版本)或Impala。或者,您可以选择自定义HiveServer2并提供自己的蜂巢罐。 |
| 自定义Hive Lib目录 | 仅选择Custom Hiveserver2.选择一个包含连接到集群所需的库(JAR文件)的目录。 |
| Hive高可用性 | 如果该集群已激活Hive High Availability(前提是HiveServer访问由ZooKeeper协调),请勾选此复选框。 |
| Hive Server Address/Impala Server Address | Hive Server或Impala Server所在节点的地址(通常为主机名)。 |
| Hive Port/Impala Port | Hive Server或Impala Server的端口。 |
| 数据库名称 | 要连接的数据库的名称。 |
| JDBC URL后缀 | JDBC URL的可选后缀。Impala连接的默认值是“auth=noSasl”。 |
| 用户名 | 连接指定数据库的用户名。对于所有HiveServer2版本的连接,默认为“hive”。该用户应该能够访问HDFS目录Radoop用来临时存储文件的。如果此目录位于加密区域,则用户还应具有访问加密区域密钥的权限。 |
| 密码 | 连接指定数据库的密码。RapidMiner Radoop使用cipher.key用于加密密码的文件radoop_connections.xml. |
| udf是手动安装的 | 如果集群中手动安装Radoop udf,请勾选。关于手动UDF安装的更多信息,可以在操作与维护页面。 |
| 为udf使用自定义数据库 | 如果使用自定义数据库存储和访问Radoop udf,请选中此框。当更多用户(拥有不同的项目数据库和授予的特权)希望使用Radoop时,这很有用。所有这些人都应该可以访问这个公共数据库。udf仍然可以自动或手动创建。 |
| udf的自定义数据库 | 仅当选中“为udf使用自定义数据库”时.定义专用于存储Radoop udf的数据库(见上文)。数据库必须已经存在。 |
| Hive在Spark / Tez容器上重用 | 如果您想从中受益,请勾选此框Hive on Spark / Hive on Tez容器重用. |
| 蜂巢主要 | 仅在启用Kerberos安全的情况下.Hive服务的负责人。格式为primary[/ |
| SASL QoP级别 | SASL保护质量等级。该设置必须与集群设置保持一致。(要找到集群设置,请找到hive.server2.thrift.sasl的值。Qop在hive-site.xml;默认为“auth”。) |
| Hive高级参数 | 键值属性来定制Hive的行为。 |
RapidMiner服务器
此选项卡包含一些影响在RapidMiner Server上执行的多用户配置设置。有关更多信息和最佳实践解决方案,请参阅相关的部分的在服务器上安装Radoop页面。
| 场 | 描述 |
|---|---|
| 在服务器上启用模拟 | 如果您想在RapidMiner服务器上使用模拟(代理)Hadoop用户,请选中此复选框。 |
| 服务器主要 | 仅在启用Kerberos安全和服务器模拟的情况下.RapidMiner Server访问集群时使用的主体。格式为primary[/ |
| 服务器Keytab文件 | 仅在启用Kerberos安全和服务器模拟的情况下.服务器计算机上的服务器keytab文件的路径。 |
| 模拟用户进行本地测试 | 仅当启用服务器上的模拟时.在Studio中模拟本地测试服务器连接的服务器用户。 |
| 访问白名单 | Regex用于访问此连接的服务器用户。将其保留为空或使用“*”来允许所有用户访问。 |
Radoop代理
| 场 | 描述 |
|---|---|
| 使用Radoop代理 | 如果您想通过访问Hadoop集群,请选中此复选框Radoop代理. |
| Radoop代理连接 | 只有启用了Radoop Proxy功能.该字段由两个下拉选择器组成,它们一起定义了用于访问集群的Radoop代理。第一个定义了Radoop代理的位置。可以是本地的,也可以是配置好的RapidMiner Server存储库之一。第二个是Radoop Proxy的标识符。 |
XML连接编辑器
属性可以手动编辑Radoop连接XML编辑XML…按钮的连接设置对话框。请注意,应该谨慎使用该特性,因为通过XML编辑器在连接条目中很容易出错。编辑器的主要目的是使连接共享和复制粘贴它的某些部分(例如。Hadoop高级参数)容易多了。当您用OK按钮关闭窗口时,您所做的更改将出现在Connection Settings对话框的字段中。
注意:添加一个单独的键属性来< radoop-connection-entry >标签在XML编辑器中将不起作用。它只能被添加进去radoop_connections.xml,手动。
配置非默认属性
如果您的Hadoop集群使用非默认属性,则可能需要额外的键-值对。像Cloudera Manager和Ambari这样的集群管理工具允许您这样做下载客户端配置文件.的文件中添加与集群连接相关的属性Hadoop高级参数部份Hadoop选项卡。请参阅下面经常(重新)设置的单个属性,以及描述连接到启用了高可用性(HA)的集群所需的属性的更复杂示例。下表列出了可能需要的客户端设置的键。这些值应该设置为来自客户端配置文件的适当属性值。注意,并不是所有与这些特性相关的键都是必需的,所需的键-值对集取决于您的集群设置。
| 关键 | 描述 |
|---|---|
dfs.client.use.datanode.hostname |
指示客户端在连接到datanode时是否应该使用datanode主机名。将其设置为true可以允许使用datanode的公共网络接口而不是私有网络接口。默认情况下,使用从集群检索的属性值。如果没有正确设置,DataNode网络测试(全连接测试的一部分)将显示警告。例如:看CDH 5.5快速入门虚拟机 |
mapreduce.job.queuename |
提交作业的队列。系统必须配置这个预定义的队列,并且必须授予向其提交作业的访问权限。当使用默认队列以外的队列时,必须在这里显式地定义。例子:low_priority |
配置到支持HA hdfs的集群的连接只需要在Hadoop高级参数部份Hadoop选项卡。
HA特性通过提供一个备用(除了活动的)NameNode来消除集群的任何单点故障。HA实现手动切换和自动故障切换,提供持续可用性。RapidMiner Radoop客户端连接集群所需的设置如下表所示。这些属性必须在每个集群节点配置文件中配置。有关更多详细信息,请参阅Hadoop文档。
| 关键 | 描述 |
|---|---|
fs.defaultFS(或fs.default.name) |
Hadoop FS的默认路径通常包含ha启用集群的NameService ID。例子:hdfs: / / nameservice1 |
dfs.nameservices |
服务的逻辑名称。例子:nameservice1 |
dfs.ha.namenodes。< nameservice ID > |
唯一的NameNode标识符列表,以逗号分隔。例子:namenode152, namenode92 |
dfs.namenode.rpc-address。< nameservice ID >。< namenode ID > |
用于侦听的每个NameNode的RPC地址。例子:node01.example.com: 8020 |
dfs.client.failover.proxy.provider。< nameservice ID > |
HDFS客户端用来联系主NameNode的类。目前Hadoop只提供了一个选项。例子:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
设置到HA资源管理器支持的集群的连接只需要在Hadoop高级参数部份Hadoop选项卡。
RM (Resource Manager) HA特性通过主备RM对消除单点故障(增加冗余)。RapidMiner Radoop客户端连接集群所需的设置如下表所示。这些属性必须在每个集群节点配置文件中配置。有关更多详细信息,请参阅Hadoop文档。
| 关键 | 描述 |
|---|---|
yarn.resourcemanager.ha.enabled |
启用资源管理器高可用性。 |
yarn.resourcemanager.ha.automatic-failover.enabled |
启用自动故障转移。缺省情况下,仅在启用HA时启用。 |
yarn.resourcemanager.ha.automatic-failover.embedded |
当自动故障转移被启用时,使用嵌入式leader-elector来选择活动RM。缺省情况下,仅在启用HA时启用。 |
yarn.resourcemanager.zk-address |
ZK-quorum地址。用于状态存储和嵌入式领导人选举。 |
yarn.resourcemanager.cluster-id |
集群标识。由选民使用,以确保RM不会接管另一个集群的活动。例子:yarnRM |
yarn.resourcemanager.ha.id |
标识集合中的RM。可选,但是如果设置了,请确保所有rm都有唯一的ID。 |
yarn.resourcemanager.ha.rm-ids |
rm的逻辑id列表,以逗号分隔。例子:rm274, rm297 |
yarn.resourcemanager.address。< rm-id > |
每个RM ID对应的业务地址。 |
yarn.resourcemanager.scheduler.address。< rm-id > |
每个RM ID的调度程序地址。 |
yarn.resourcemanager.resource-tracker.address。< rm-id > |
每个RM ID的资源跟踪器地址。 |
yarn.resourcemanager.admin.address。< rm-id > |
每个RM ID对应的RM admin地址。 |
yarn.resourcemanager.store.class |
用于RM恢复的持久存储的类。 |
为RapidMiner Radoop连接配置Spark
通过为RapidMiner Radoop连接配置Spark,可以启用Spark操作符。上的每个操作符的确切Spark版本要求在Studio上安装Radoop页面。
若要启用Spark,请选择有效的火花版本中的下拉列表中连接设置对话框。
上必须提供以下强制输入火花的标签。连接设置对话框:
| 场 | 描述 |
|---|---|
| 火花版本 | 下拉列表以选择集群支持的Spark版本。
|
| 程序集Jar位置/ Spark Archive(或lib)路径 | 分布式Spark程序集JAR文件/ Spark JAR文件的HDFS或本地路径。如果您提供了本地路径,那么它在集群中的每个节点上都必须相同。如果集群上自动安装了Spark(例如Cloudera Manager或Ambari),建议指定本地路径。对于某些Hadoop版本,可以从上面下载预构建的Spark程序集JARApache Spark下载页面.一些供应商(如Cloudera)提供了特定于发行版的Spark程序集JAR。JAR所在的HDFS路径请联系Hadoop管理员。以手动安装Spark 1.5为例,请参考Spark需求部分.如果你按照那里的说明,你的程序集jar在HDFS上的以下位置:hdfs: / / / tmp / / spark-assembly-1.5.2-hadoop2.6.0.jar火花 |
| Spark资源分配策略 | Spark需要指定允许使用的集群资源。乐鱼体育安装参见Spark资源分配策略描述 |
| Spark高级参数 | 可应用于Spark-on-YARN作业的键-值对。如果更改对您的Spark作业没有影响,那么YARN本身很可能会忽略它。属性中的属性应用程序日志,设置spark.logConf为true。 |
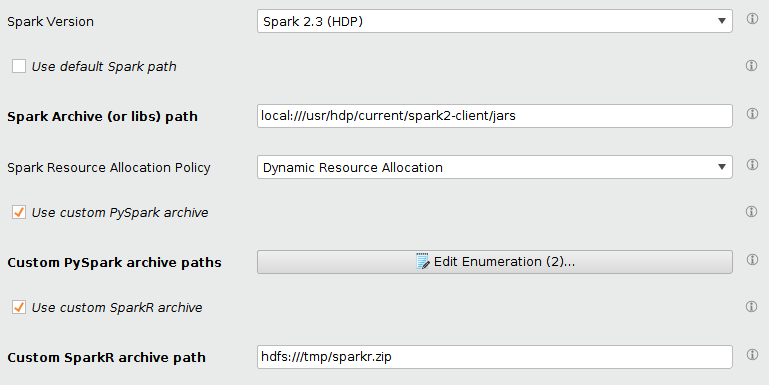
为Spark配置自定义PySpark/SparkR档案
Radoop为每个小(x.y) Spark版本提供了PySpark和SparkR存档来支持火花脚本操作符。在大多数情况下,对所有子版本(x.y.z)使用这些存档就足够了。然而,Hadoop发行版发布的某些Spark小版本(例如2.2和2.3)有多个不兼容的补丁版本,从Python/R进程<-> JVM通信方面表现不同。这些小版本不能通过发送一组归档来解决。因此在连接编辑器中引入了自定义PySpark和SparkR存档选项。启用这些选项后,Radoop将使用用户提供的存档文件来执行火花脚本而不是捆绑了Radoop的软件。这些存档通常随Hadoop发行版和Spark一起发布,所以通常位于Spark安装文件夹附近。此功能由以下额外设置处理:
| 场 | 描述 |
|---|---|
| 使用自定义PySpark存档 | 如果您想提供自己的服务,请选中此框PySpark档案。 |
| 自定义PySpark归档路径 | 仅当启用“使用自定义PySpark存档”选项时。用作PySpark库,PySpark作业提交。您通常需要在这里提供两个存档文件,pyspark.zip和py4j-*.zip。这些文件的确切名称和访问路径取决于集群的Hadoop和Spark版本。因为您需要提供至少两个项,所以这个参数接受多个值。每个条目都可以作为HDFS位置(hdfs:// protocol),作为在同一位置的所有集群节点上可用的文件(local:// protocol),或者作为客户端机器上的文件(file:// protocol)。在示例HDP 3环境中,使用本地路径的必要条目如下本地:/ / / usr /黄芪丹参滴丸/电流/ spark2-client / python / lib / pyspark.zip而且本地:/ / / usr /黄芪丹参滴丸/电流/ spark2-client / python / lib / py4j-0.10.7-src.zip. |
| 使用自定义SparkR存档 | 如果您想提供自己的服务,请选中此框SparkR档案。 |
| 自定义SparkR存档路径 | 仅当启用“使用自定义SparkR存档”选项时。档案用作SparkR库SparkR作业提交。此路径可以作为HDFS位置(hdfs:// protocol)或作为客户端机器上的文件(file:// protocol)。警告!此参数不支持指定集群节点上可用的存档(local:// protocol)。因此,如果您的存档可以在集群节点上访问,您将首先需要将其上传到HDFS,并使用该参数的HDFS位置。在示例HDP 3环境中,此文件位于/usr/hdp/current/spark2-client / R / lib / sparkr.zip.在下面的示例中,此文件被上传到hdfs: / / / tmp / sparkr.zipHDFS位置,然后由该参数引用。 |
Spark资源分配策略
RapidMiner Radoop支持以下资源分配策略:
动态资源分配
默认选项,从8.1.1开始。虽然此策略需要在服务器上进行配置,但许多服务器已经安装了该策略。
使用此策略,您可能需要在集群上配置外部shuffle服务。有关所需集群配置步骤的详细信息,请参见Spark动态分配文档.
下面可以定义以下属性Spark高级参数在火花选项卡的连接设置对话-它们只在以下情况下是强制性的Spark 1.4或以下版本为火花版本:
——“spark.dynamicAllocation。minExecutors - spark.dynamicAllocation.maxExecutors集群特定信息
静态、启发式配置
- 这是8.1.0及以前版本中的默认策略。如果使用此选项,则不需要设置任何高级资源分配设置。的资源分配%field设置用于Spark作业的集群资源(集群内存,内核数)的百分比。乐鱼体育安装注意,如果您将这个值设置得太高,集群上的其他作业可能会受到影响。默认值为70%。
静态、默认配置
- 使用Spark默认设置进行资源分配的策略。这个值非常低,可能不支持真正的集群,但对于虚拟机/沙箱来说可能是一个可行的选项。
静态、手动配置
- 此策略要求您在下面设置以下属性Spark高级参数在火花的标签。连接设置对话框。的火花的文档描述每个属性。(相应的Spark on YARN命令行参数显示在括号中。)
spark.executor.cores(——executor-cores)spark.executor.instances(——num-executors)spark.executor.memory(——executor-memory)- (可选)
spark.driver.memory(——driver-memory)
请注意:因为火星- 6962, RapidMiner Radoop修改默认值spark.shuffle.blockTransferService来nio而不是网状的.要重写此设置,请使用Spark高级参数字段配置密钥spark.shuffle.blockTransferService到价值网状的.从1.6.0开始,Spark将忽略此设置BlockTransferService总是网状的.
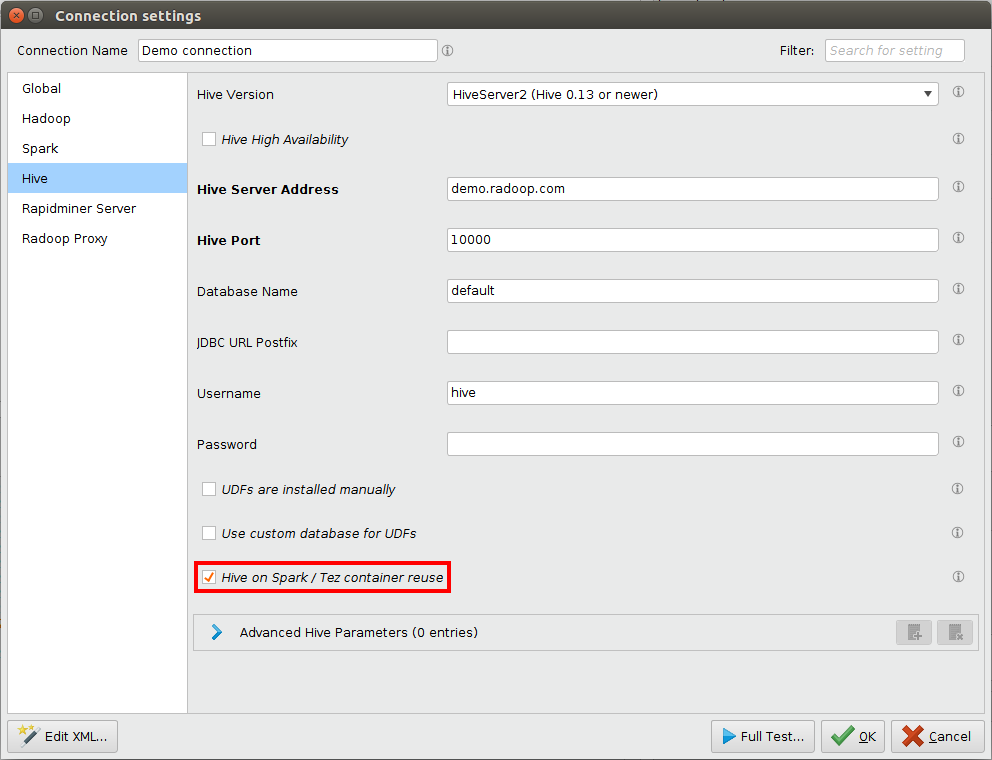
Hive on Spark & Hive on Tez容器重用
重用Hive执行引擎的容器可以极大地提高Radoop进程的速度,特别是在有很多Hive专用任务的情况下。它通过保持许多Spark / Tez容器(应用程序)处于运行状态来执行Hive查询。请记住,即使没有运行的进程,这些容器也将使用集群资源。乐鱼体育安装默认情况下,Radoop会尝试估计最佳的容器数量,但它也可以在设置中更改为固定的数量(见下文)。空闲容器超时后自动关闭。
要使用此功能,您的集群必须支持Hive on Spark或Hive on Tez,并且在您的连接中必须设置hive.execution.engine来火花或特斯在Hive高级参数并检查Hive在Spark / Tez容器上重用复选框(这是默认值):
可以使用许多全局Radoop设置来控制容器重用行为。您可能希望测试不同的设置以最佳地使用您的集群,参见Radoop设置获取详细信息。
由于Hive on Spark / Hive on Tez容器一直在运行并预留集群资源,如果运行其他MapReduce、Spark或Tez作业,在小型集群(如快速乐鱼体育安装启动虚拟机)上很容易耗尽内存/内核。为了避免这种情况,Radoop会在启动MapReduce或Spark作业前自动停止这些容器。(闲置容器无论如何都会被关闭,但这使得它们可以在空闲超时之前关闭,就在需要资源的时候。)乐鱼体育安装
黑斑羚连接
如果你正在配置一个Impala连接Hadoop高级参数需要手动添加。如果您忘记添加其中的任何一个,将会有一个警告消息提醒您缺少这些信息。的添加必填表项按钮将这些属性的键添加到列表中,但它们的值必须根据集群配置手动设置。

升级RapidMiner Studio或Server时在美国,进一步的设置可能成为强制性的,这可能意味着黑斑羚连接可能必须更新为新的所需的高级设置。