您正在查看的是RapidMiner Radoop 9.2 -版本文档查看最新版本
RapidMiner Radoop操作符
介绍Radoop操作符组。有关这些操作符的完整列表,请参见RapidMiner Radoop操作符参考(PDF).
当你安装RapidMiner Radoop扩展时,RapidMiner Studio的Radoop操作符组中有几个新的操作符可用:
为了帮助理解在哪里查找某些函数和可用的不同类型的操作符,本节提供了每个操作符组的概述。有关完整的操作符描述,请参阅RapidMiner Studio中的帮助文本。
这里提到的所有操作符都是Extensions组中Radoop操作符组的一部分。具有相同名称的操作符可以作为标准RapidMiner操作符的一部分存在。Radoop操作符列在Radoop文件夹中,也由不同的图标表示(例如![]()

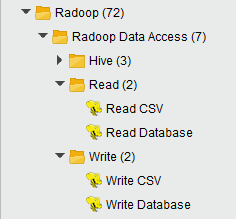
数据访问组
操作符的一部分数据访问组:
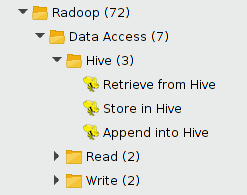
蜂巢子群
操作符的一部分蜂巢子群:
请注意:为了便于阅读,下文以简写的形式提及它们。
进程访问Hive表中已经驻留在集群中的数据检索操作符。检索只将引用和元数据加载到内存中;数据保留在集群上,由进一步的操作符处理。连接的输出端口检索直接到Radoop巢输出以从内存中获取数据样本。
的商店而且附加操作员将输入端口上的数据写入Hive表。通常这是很耗时的,因为在将数据写入HDFS之前,集群必须执行之前数据处理操作员定义的所有任务。附加验证其输入的数据是否符合指定的Hive表。
您还可以在这个子组中的所有操作符中从任意其他Hive数据库中选择表。
阅读小组
数据必须驻留在集群中,供Radoop操作员处理和分析。较小的数据集可以装入内存;当您将一个示例集连接到一个Radoop巢输入端口,Radoop导入。对于较大的数据集,使用读组-任选读CSV或读数据库.
读CSV从客户端、HDFS或Amazon S3上的文件创建Hive表。在向导的帮助下,您可以定义分隔符和属性的名称(或设置从文件中读取它们),以及修改类型或设置属性角色。
读数据库从数据库中查询任意数据,并将结果写入集群。数据库必须可以从客户端访问,客户端将数据写入HDFS(只使用最小的客户端内存占用)。Radoop支持MySQL, PostgreSQL, Sybase, Oracle, HISQLDB, Ingres, Microsoft SQL Server或任何其他使用ODBC桥的数据库。如果您希望以直接或并行的方式从数据库导入(将客户端排除在路由之外),请寻找类似的解决方案Sqoop.
写群
写操作符(写CSV而且写数据库)将HadoopExampleSet引用的数据写入到客户端的平面文件中。或者,它们可以通过指定的数据库连接将数据写入数据库。的商店可使用operator将数据写入HDFS或S3。
本指南包含更详细的信息数据导入操作符。
混合组
这是最大的Radoop操作员组;它包含组织成子组的所有混合运算符。操作符通常以HadoopExampleSet作为输入,并有两个输出端口——一个用于转换后的HadoopExampleSet,另一个用于原始的HadoopExampleSet。在设计时,将鼠标悬停在第一个输出端口上,以检查转换后的结构或元数据。
类的子组和操作符是混合组:
有两个可以接受多个输入的标准转换操作符。用于组合多个数据集(HadoopExampleSet对象)使用加入或联盟来自集合操作组。加入实现关系数据库中常见的四种类型的连接操作—内部、左、右或全外部—并具有两个输入端口和一个输出端口。联盟接受具有相同结构的任意数量的输入数据集。输出数据集是这些输入数据集的并集(重复的数据不会被删除)。
可以使用Radoop中的一种脚本操作符实现自定义转换。它们可以在Utility/Scripting组中找到。
净化集团
该组包含执行数据清理的操作符。就像混合group,这些操作符也接收HadoopExampleSet作为输入,并有转换后的和原始的HadoopExampleSet输出。属性可以管理输入数据集的缺失值替换缺失值或者是声明缺失值运算符来消除重复的示例删除重复的操作符。
正常化而且主成分分析有一个预处理模型输出。它可以用于在另一个数据集(具有相同的模式)上执行相同的预处理步骤。要做到这一点,请使用应用模型的运算符得分组。
模型组
除了ETL操作符,Radoop还包含用于预测分析的操作符。这个组中的所有建模算法都使用MapReduce范式或Spark来充分利用分布式系统的并行性。它们可以根据集群上的大量数据进行扩展。本节只列出操作符;请参阅有关Radoop的预测分析功能为了进一步解释。
该组中的操作符处理与核心RapidMiner操作符相同类型的模型对象。因此,Radoop操作符的模型输出可以连接到核心RapidMiner操作符的输入端口,反之亦然。在集群上训练的模型可以以与在运算记忆数据集上训练的模型相同的方式进行可视化。性能向量对象也具有相同的兼容性,这些对象包含用于检查和比较模型性能而计算的性能标准值。这些对象还可以在操作集群的操作符和使用操作内存的操作符之间轻松共享。
操作符的一部分建模组:
预测子群
这一组中的大多数运营商实现分布式机器学习算法用于分类或回归。它们的预测模型建立在集群上的输入hadoopexampleeset上。该模型既可以应用于集群上的数据(请参阅得分操作符组)或将数据移到运算存储器中应用模型core RapidMiner操作符。
更新模型实现增量学习(仅适用于朴素贝叶斯模型)。增量学习意味着基于新的数据和新的观察,对现有模型进行修改,即更新其属性。因此,机器学习算法不必在整个数据集上建立一个新的模型,它通过在新的记录上训练来更新模型。操作人员的预期输入是先前建立的模型和与建立模型的数据集具有相同结构的数据集。
的结合模型算子将其输入端口上训练好的预测模型组合成一个简单的投票模型——a装袋模型.
分割子群
的分割Group包含三个不同的聚类操作符。它们每个都在输入时期望一个HadoopExampleSet对象,并在输出时传递修改后的HadoopExampleSet对象。算法添加一个包含聚类结果的新列;也就是说,由标称标识符(cluster_0,cluster_1,cluster_2等)。这些值标识属于同一个集群的行。
输入数据必须具有唯一标识行的ID属性。属性必须具有“ID"角色(使用设置角色操作符)。如果数据集中没有ID列,则可以使用Radoop的ID列生成ID操作符来创建一个。
子群的相关性
的相关矩阵而且协方差矩阵运算符计算输入数据集中属性之间的相关性和协方差。相关性显示了属性对之间的相关性有多强。协方差度量两个属性一起变化的程度。
评分小组
的得分组包含应用模型操作符。它将模型应用于其输入端口上的数据,并支持所有RapidMiner预测模型。您可以在内存中的ExampleSet或Hadoop集群中的Radoop操作符上使用RapidMiner建模操作符训练模型。操作员可以同时应用预测和聚类模型。
验证组
操作符的一部分验证组:

的性能(双名分类),性能(分类),性能(回归)每个操作符都需要一个HadoopExampleSet对象作为输入,该对象具有标签和预测标签属性。每个运算符比较这些结果并计算性能。您可以使用操作符的参数选择性能标准。生成的包含这些值的性能向量对象与核心RapidMiner操作符使用的I/O对象完全兼容。
的分割验证算子随机地将一个exampleeset分成训练集和测试集,这样模型就可以使用其中一个性能算子进行评估。
公用事业集团
这个组包含许多强大的操作符,其中一些需要一些RapidMiner Radoop的经验才能使用。的操作符中有以下操作符实用程序组:
的子流程操作符允许您在进程中运行进程。这个操作符对设计清晰和模块化的流程有很大帮助。的乘如果您想在进程的不同分支中使用相同的HadoopExampleSet对象,则必须使用operator。操作符只是将其输入端口上的对象传递到每个连接的输出端口。
的实现数据运算符对输入数据集执行所有延迟计算,并将数据写入分布式文件系统(写入临时表)。的乘运算符只是将所选输入对象相乘。
蜂巢子群
在这个组中,3个表管理操作员对Hive表进行典型的管理操作。例如,你可以使用下降之前一个附加操作符,以确保新进程运行从一个新表开始。这两个重命名而且复制可以在更复杂的进程(例如,包含循环)中提供帮助,或者可以管理在它们之前或之后运行的其他进程的表。这些要被操作的表可以来自用户可以访问的任何Hive数据库。
脚本的子群
要对数据执行自定义转换,您可以使用Hadoop之上的三种最流行的脚本语言之一:蜂巢,猪,火花.蜂巢脚本,猪的脚本,火花脚本操作符脚本组允许您编写自己的代码。这三种脚本都可以接受多个输入数据集,Pig Script和Spark Script可以提供多个输出数据集。Hive Script和Pig Script操作符在设计时确定元数据,并检查脚本是否包含语法错误。Spark Script操作符不处理其输出上的元数据,也不检查语法错误。语法高亮显示可用于Python中的Spark脚本。
过程控制子组
的过程控制子组包含与组织流程步骤相关的操作符。在循环运营商子群,循环属性遍历数据集的列,并在每次迭代中执行任意的Radoop子进程。一般循环运算符执行其内部子进程的次数是任意的。
本地内存计算子组
的本地内存计算子组包含操作符,帮助您将集群中的处理与内存中的处理结合起来。内存子进程(示例)从集群中的数据集中获取一个样本到内存中,并在那里的样本上执行其内部子进程。这个子进程可以使用数百个核心RapidMiner操作符中的任何一个。内存处理(满)是类似的,但是它通过执行类似于样本的版本。也就是说,它将输入数据集划分为n块,然后在与的循环中对每个块运行其内存中的子进程n迭代。它可以附加这些子流程的结果数据集,在集群上创建输出数据集。请参阅有关先进工艺设计更多细节。
Process Pushdown子组
这个组包含Rapidminer Radoop中最强大的操作符之一单流程下推.这个元操作符可以包含来自RapidMiner Community Edition和大多数扩展(例如文本处理,Weka)的任何操作符。类中的子进程单流程下推推送到其中一个集群节点,并使用该节点的内存执行。结果可以在输出中作为HadoopExampleSet(第一个输出端口)或内存中的IOObject,如模型或性能向量(其他输出端口)。关于此操作符的更多信息和进一步提示,可以在先进工艺设计页面。
随机数据生成子组
如果您需要Hive上的大数据用于测试目的,请使用生成数据这组中的操作员。利用选定的目标函数计算标签值,可以生成大量的数值数据。