您正在查看的是RapidMiner Radoop 9.2 -版本文档查看最新版本
先进的Radoop进程
为了理解先进的Radoop流程设计,您应该熟悉RapidMiner数据流,Radoop基础知识,如何导入数据.以下部分将介绍RapidMiner Radoop的预测分析功能,并通过使用相同的I/O对象、元数据和进程设计概念,说明它如何顺利地集成到RapidMiner客户机接口中。但是,因为Radoop在Hadoop中实现了操作,所以您可以在集群上部署您的进程(或其选定的一部分),以使用可伸缩的分布式算法管理巨大的数据量。
模型对象
数据挖掘方法,主要是监督学习算法,创建预测模型。(其他算法生成其他类型的模型,但本节主要关注预测和聚类模型。)这些模型描述了从训练数据集中探索的信息。RapidMiner模型是一个I/O对象预测模型,集群模式,或预处理模型-就像一个ExampleSet对象。模型的可视化向用户显示了所探索的信息。
Radoop和核心RapidMiner操作符训练和应用相同类型的模型对象。更准确地说,Radoop在分布式基础设施上实现了一些流行的RapidMiner模型的评分和学习;所有核心预测模型现在都可以应用在集群上。这不仅适用于预测模型,也适用于预处理模型,例如,预处理算子,添加噪声,生成(噪声模型)。
与建模相关的另一种类型的I/O对象是性能向量对象。以模型的形式进行预测,通过将预期目标属性值与评分结果进行比较来评估。有了这个结果,性能标准从数据挖掘过程目标的角度创建了描述预测(模型)有效性的度量。换句话说,Radoop在集群上执行评分和模型应用程序以及性能标准计算。
数据挖掘场景
本节回顾用于预测建模过程的一些可能的内存/集群场景。
Hadoop中的无监督学习.在这个场景中,可伸缩的分布式算法在Hadoop中创建数据集群。一些聚类算法构建的聚类模型可以应用于其他类似的数据集,无论是在Hadoop上还是在内存中。模型在集群模式(clu)聚类操作符的输出端口。
记忆中的监督学习,聚类评分.Core RapidMiner建模(分类和回归)操作符在内存中构建预测模型,然后可以将其应用于集群中的数据。Radoop支持应用所有核心预测模型。通过使用SparkRM或单流程下推使用任何核心RapidMiner建模算子,学习可以在一个或多个集群节点的内存中并行执行。
在集群上使用本地算法进行监督学习和评分.在这个场景中,学习和评分都是在分布式平台上实现的。Radoop支持以下算法:朴素贝叶斯、线性回归、逻辑回归、支持向量机、决策树和随机森林。它还支持迭代朴素贝叶斯模型构建,这意味着模型(构建在集群上或内存中)可以通过新数据(在集群上或内存中)进行更新。
聚类模型
Radoop集群运营商都是建立在分布式机器学习算法上的Apache Mahout项目。集群操作符的输入是一个HadoopExampleSet对象。该算法在数据中创建指定数量的段。它向数据集添加一个名为clusterid,它有集群的角色。该属性包含集群标识符cluster_1,cluster_2等。
聚类运算符还可能表明某条记录与其他记录相距太远,因此应将其视为离群值。在本例中,cluster属性包含该值离群值.
k - means而且模糊k - means算法还建立了质心聚类模型。可以使用质心模型对驻留在集群上或内存中的类似结构的数据集进行聚类。
分类和回归模型
可以连接由客户端机器内存或集群节点内存中的核心RapidMiner操作符训练的预测模型和集群模型SparkRM或单流程下推操作符)到a的输入端口Radoop巢并在子进程中使用它们。Radoop的应用模型Operator接受这样一个模型和一个测试数据集作为输入。操作符将预测模型应用于HadoopExampleSet输入,并交付一个包含新的预测和置信度列的HadoopExampleSet。在集群模型中,Radoop生成一个集群列。
Radoop支持对所有RapidMiner预测和集群模型进行集群评分。这些模型在相同的数据集上在巢内和巢外产生相同的预测,但在巢内评分不限于操作内存大小;它可以在分布式平台上扩展。
您还可以在分布式平台上训练预测模型。Radoop支持朴素贝叶斯,线性回归,逻辑回归,支持向量机,决策树和随机森林学习算法。这些算法具有以下特点:
| 算法 | 属性类型 | 类类型 | 笔记 |
|---|---|---|---|
| 朴素贝叶斯 | 数值和名义 | 多词学名 | 包含一个独特的、线性可扩展的朴素贝叶斯实现。非常适合迭代学习。 |
| 线性回归 | 数值 | 数字和二项式 | 集成Spark MLlib实现。 |
| 逻辑回归 | 数值 | 二名式命名法 | 集成Spark MLlib实现。 |
| 支持向量机 | 数值 | 二名式命名法 | 集成Spark MLlib实现。 |
| 决策树 | 数值和名义 | 二项式和多项式 | 的决策树(MLlib二名)集成了Spark MLlib实现,可以处理双名标签决策树操作员处理多标号和集成火花。曼梯·里的算法。 |
| 随机森林 | 数值和名义 | 多词学名 | 集成了火花。ml的随机森林算法。 |
您可以以同样的方式应用用上述算法训练的模型,使用核心应用模型操作符(内存中)和Radoop应用模型运营商(可能在hadoop)。
迭代学习
迭代学习是用于分类或回归任务的一种特殊类型的学习。随着每一次迭代,Radoop更新该模型采用了新的训练数据集。由于使用新记录进行更快的更新会产生相同的模型,因此您可以只使用新记录重新构建模型,就像使用整个新数据集构建模型一样。这是大数据分析中非常常见的场景(例如,新的日志记录可能会定期更新预测模型)。
类实现了迭代学习更新模型操作符。该操作符以一个模型作为输入(a分布模型它是用朴素贝叶斯构建的),并通过在它的另一个输入端口上的hadoopexampleeset上进行训练来更新它。输入模型可以由Radoop学习操作符(基于exampleeset创建模型的操作符,如朴素贝叶斯)或核心RapidMiner学习器进行训练。新的数据集必须具有与原始训练数据集完全相同的模式。也就是说,名称和属性类型必须匹配,但顺序无关。的学习算法更新模型运算符可能有(也可能没有)参数,例如优化参数。因此,更新模型Operator有一个特殊的“泛型”参数,允许您轻松指定模型类型的特定参数。(例如,如果更新模型在输入上有一个DistributionModel,您可以设置名义组大小训练参数。)
下面演示了在单个子流程中更新和应用模型:
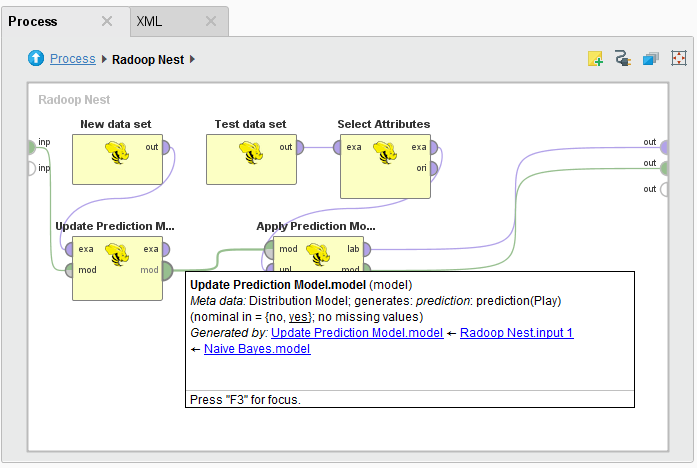
整体建模
Radoop包含一个名为结合模型.对象的内部和外部都可以使用此运算符Radoop巢.它只是创建了一个装袋模型——有时被称为投票模型——从训练过的模型中提取输入。(请注意,所有输入模型都必须在具有相同模式的数据上进行训练。)输入可以是模型的集合,也可以是输入端口上任意数量的模型。输出端口上的集成模型将是一个投票模型。如果用这个模型打分,它应用所有的内部模型,然后取置信值的平均值(如果是分类模型)来决定预测的类别。在回归模型(有数值标签)的情况下,它计算内部模型预测的平均值。
你可能想使用结合模型如果您在集群上有太多的训练数据,并且由于某种原因,Radoop提供的分布式算法不适合您的用例,则使用operator和训练循环。您可以从数据中获取随机样本到内存中,并在这些样本上训练不同的模型。在将这些模型组合到一个Bagging Model之后,您就可以将该模型直接应用于集群上的数据。通过这种方式,您不仅使用了RapidMiner广泛的学习算法,而且只使用数据样本在短时间内构建了一个非常精确和健壮的集成模型。
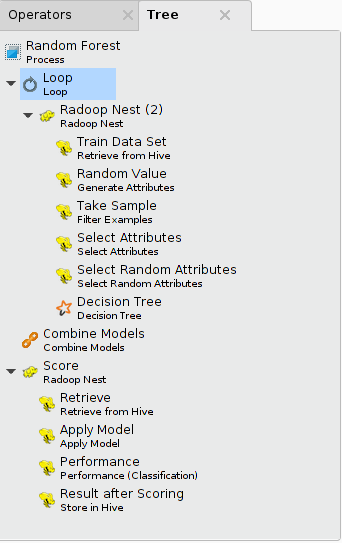
您还可以在每次训练迭代中仅使用常规属性的子集来构建更精确的投票模型。的选择随机属性Operator是这项任务的理想选择。对于训练算法,RapidMiner Radoop的决策树学习算法可能是一个很好的选择。通过这种方式,您可以实现,例如,a随机森林学习算法,控制样本大小,迭代次数,以及基于可用资源(内存,带宽,数据量)的随机化方法。乐鱼体育安装您可以使用任何不稳定的学习算法来代替决策树,从而受益于结合模型算子,因为Radoop支持用单个算子以分布式的方式构建随机森林模型。
下面演示了在数据样本上实现随机森林训练算法的过程(100次迭代的循环)。它使用树面板上显示所有的操作程序。你可以打开树控件来设置流程查看>显示面板>树菜单项。
内存中的子流程
RapidMiner Radoop提供了多种方法来利用RapidMiner的内存操作符。的内存子进程(示例)而且内存子进程(满)运算符以一种更通用的方式实现前一节中描述的概念。它们都作用于行的子集。这些运算符对于训练集合模型非常有用,但是内存子进程(满)还能够执行其他预处理任务。不像内存中的子流程,SparkRM而且单流程下推操作符能够在集群节点上使用节点的可用内存.通过这种方式,您可以使用Hadoop集群的资源来执行任何内存中的计算任务。乐鱼体育安装
使用集群的内存
的SparkRM而且单流程下推操作符可用于在一个或多个集群节点上执行内存中的子进程。他们的详细描述在流程下推子页.
使用客户端机器的内存
由于大型数据集驻留在集群上,并且集群节点预期拥有比客户端机器(在本例中运行Studio或Server)更多的资源,乐鱼体育安装SparkRM而且单流程下推应优先考虑在下面描述的两个(在某种意义上,遗留的)操作符之上。
内存子进程(示例)元素中的元操作符Radoop巢它在操作内存中的数据样本上运行子进程。的HadoopExampleSet中获取一个样本内存子进程(示例)输入端口到内存,子进程-由任何核心RapidMiner操作符组成-应用于该数据。然后将数据写回HDFS,供Radoop进程进一步处理。您可以将其他I/O对象(例如,在此示例数据上训练的模型)连接到输出端口,以便以后在集群上使用。请注意SparkRM或单流程下推操作符优先于内存子进程(示例)因为它们执行相同的操作,但使用集群的资源而不是客户端机器的资源。乐鱼体育安装
内存子进程(满)与示例版本的不同之处在于:它在适合操作内存的小分区中处理输入端口上的所有数据。您必须定义输入数据将被分割到的这些分区的数量或分区的大小。元操作符在这些分区上执行循环。在每次迭代中,它将当前分区中的数据读入内存,在其上运行子进程,然后将数据写回HDFS(将其追加到输出表中)。
的使用基本上有两种不同的场景内存子进程(满)元操作符:
当你想做特殊的数据预处理时,你不能用Radoop操作符实现,但可以用核心RapidMiner操作符(或来自其他扩展的操作符)。在这种情况下,使用元操作符可以在预处理数据时通过客户端的操作内存传输数据。由于运行内存和/或网络带宽可能会限制这一点,较大的数据集最好使用RapidMiner Server。您的服务器可能有足够的内存和良好的连接来处理较大的输入数据(较大的分区意味着更少的迭代)。
当您使用分割构建对象时,您不需要将数据写回集群。例如,类似于前一节中的随机森林示例,您可以将任意多的决策树模型训练到任意多的分区(即“输出决策树的数量”=“分区的数量”)。然后,可以将这些模型组合为投票模型结合模型操作符。要做到这一点,请连接在内存子进程(满)元运算符到输出,然后连接<决策树的集合元操作符的>输出结合模型输入。通过这种方式,您可以在比运算内存大小大得多的数据上训练模型,但仍然可以期望投票模型具有相当好的精度。
就像内存子进程(样例)一样,内存子进程(满)可以被单进程下推所取代。如果数据大于集群中最大节点的内存,则可以使用生成属性操作符来创建一个随机属性和滤波器的例子在循环中为Pushdown操作符创建分区。
评价
性能评估算子的目的是为评估当前预测和预测模型本身提供简单的度量。分析人员可以定义他们想要优化的目标度量,并且可以使用这些性能标准对模型进行比较。
Radoop实现了评估二名和多名分类和回归的方法。这些构成了核心RapidMiner计算操作符实现的标准集的子集。下面的性能标准列表描述了这些措施。
| 类型 | 标准名称 | 标准描述 |
|---|---|---|
| 二项式和多项式 | 精度 | 正确分类示例的相对数量 |
| 二项式和多项式 | classification_error | 错误分类示例的相对数量 |
| 二项式和多项式 | 卡巴 | 卡帕统计分类 |
| 二名式命名法 | 精度 | 在所有被分类为阳性的例子中,正确被分类为阳性的例子的相对数量 |
| 二名式命名法 | 回忆 | 在所有正例中正确作为正分类例的相对数量 |
| 二名式命名法 | 电梯 | 正面阶级的提升 |
| 二名式命名法 | 影响 | 在所有的反面例子中,错误地作为正面例子分类的相对数量 |
| 二名式命名法 | f_measure | 精度和召回率的组合:f=2pr/(p+r) |
| 二名式命名法 | false_positive | 错误地作为正面分类示例的绝对数量 |
| 二名式命名法 | false_negative | 错误归为否定分类的例子的绝对数量 |
| 二名式命名法 | true_positive | 正确作为正分类实例的绝对数量 |
| 二名式命名法 | true_negative | 正确作为反面分类示例的绝对数量 |
| 二名式命名法 | 灵敏度 | 所有正例中正确作为正分类例的相对数量(与回忆相同) |
| 二名式命名法 | 特异性 | 所有反例中正确作为反分类例的相对数量 |
| 二名式命名法 | youden | 敏感度和特异性之和减去1 |
| 二名式命名法 | positive_predictive_value | 在所有正分类样例中正确为正分类样例的相对数量(与精度相同) |
| 二名式命名法 | negative_predictive_value | 在所有被归类为否定的例子中,正确被归类为否定的例子的相对数目 |
| 二名式命名法 | psep | 正预测值和负预测值之和减去1 |
| 多元和回归 | absolute_error | 预测值与实际值的平均绝对偏差 |
| 多元和回归 | relative_error | 平均相对误差(预测值与实际值的绝对偏差除以实际值的平均值) |
| 多元和回归 | relative_error_lenient | 平均宽松相对误差(预测值与实际值的绝对偏差除以实际值与预测值的最大值的平均值) |
| 多元和回归 | relative_error_strict | 平均严格相对误差(预测值与实际值的绝对偏差除以实际值与预测值的最小值的平均值) |
| 多元和回归 | root_mean_squared_error | 平均均方根误差 |
| 多元和回归 | squared_error | 平均平方误差 |