您正在查看的是RapidMiner Radoop 9.2 -版本文档查看最新版本
SparkRM:过程下推
单流程下推而且SparkRM是元操作符,在一个(单流程下推)或多个(SparkRM) Hadoop集群节点。
元操作符中的子流程可以包含RapidMiner Studio中的任何核心操作符。此外,也可以使用外部扩展(例如Weka, Text Processing),它们由客户端(Studio或Server)自动上传到集群。目前还不支持少数操作符,例如与数据库处理相关的操作符和Execute Script操作符。您还可以设置RapidMiner Studio或任何扩展的非默认首选项设置配置参数参数。这是特别有用的,例如当使用Python脚本扩展,其中Python安装目录必须通过首选项设置提供。
对于这两个操作符,您可以为您的数据设置采样(默认禁用)。宏可以由内部操作符使用、创建和操作,并且可以在子流程中引用Samples存储库。
单流程下推
单流程下推在第一次输入时接受任意大的HadoopExampleSet,在随后的输入端口上接受任何IOObject。同样,它在第一个输出上交付一个大的hadoopexampleeset,在其他输出端口上交付任何IOObject。
请注意,只有第一个输入/输出端口可以处理大数据,其他端口将对象临时存储在客户端机器的内存中,因此,它们只能用于模型、性能向量、小表等。
关于操作器端口和参数的进一步考虑可以在RapidMiner Radoop操作符参考(PDF).Samples存储库可以通过检索子流程中的操作符,其他存储库则不是,因此它们必须连接到其中一个操作符输入端口。
下面的示例过程演示了单流程下推接线员:
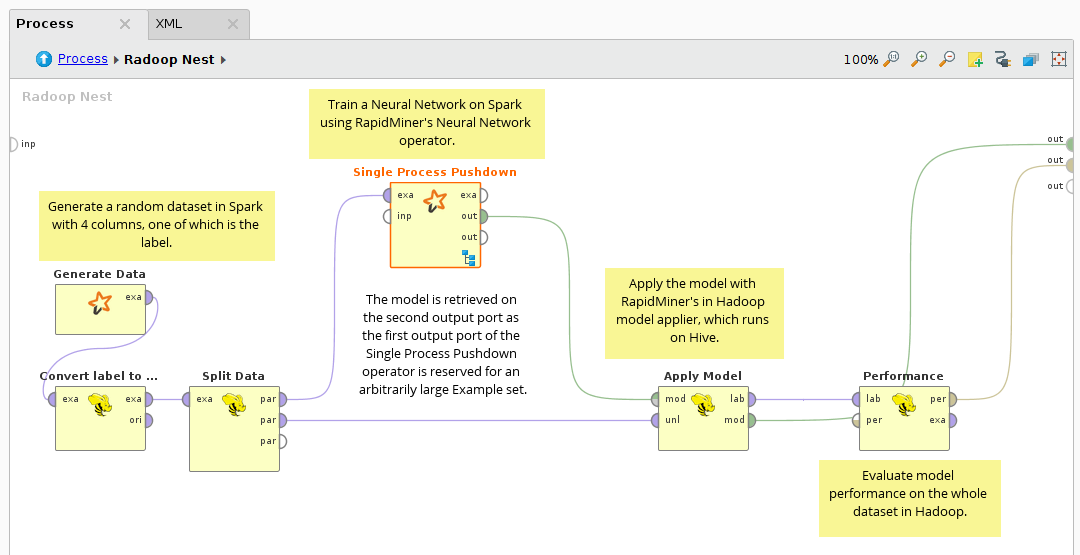
里面的子进程单流程下推:
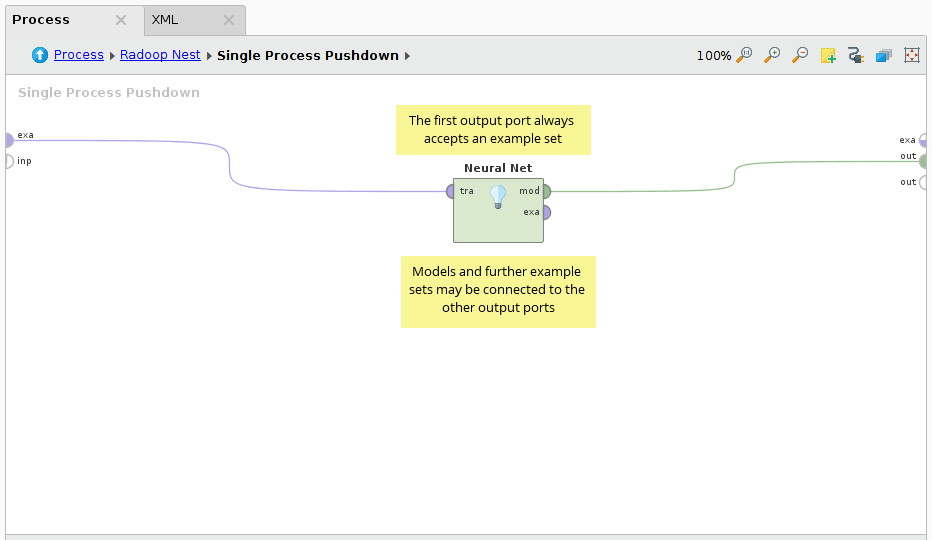
神经网络是最精确的学习算法之一。在这个过程中,RapidMiner的神经网络操作符用于输入hadoopexampleeset,该输入hadoopexampleeset是使用生成数据操作符。由于标签总是数值的,所以它首先转换为双名。分割数据用于创建训练和测试数据集。的神经网络运算符用于单流程下推建立模型。最后,利用RapidMiner Radoop的分布式软件将神经网络模型应用于测试数据应用模型操作员和性能向量被计算出来。
SparkRM(并行过程下推)
的SparkRM元运算符是RapidMiner Radoop中最独特的运算符。它能够使用多个集群节点并行执行RapidMiner进程。
就像Single Process Pushdown一样,操作符有一个Example Set输入端口和一个Example Set输出端口(第一个输入和输出端口)。运算符在输入端接受一个任意大的HadoopExampleSet,并在输出端提供一个大的HadoopExampleSet。操作符的其他输入和输出端口用于进一步的ioobject(模型、性能向量、小示例集等)。
请注意,只有第一个输入/输出端口可以处理大数据,其他端口将对象临时存储在客户端机器的内存中,并且它们也在执行期间分布到所有分区。因此,这些端口应该只用于模型、性能向量、小表等。
SparkRM的核心概念是分区.当操作符执行时,第一个输入端口上的数据根据操作符的分区被分割分区模式以及相关参数。然后在所有这些分区上执行子进程,最好是并行执行(在集群资源允许的范围内)。乐鱼体育安装可以使用多个集群节点并行地执行该流程,一个集群节点可以并行地处理多个分区。分区方式如下:
- 线性:默认分区模式。当使用线性分区时,分区的数量与输入数据的大小成比例。每个分区的大小取决于集群上HDFS块的大小。如果不想指定确切的分区数量,并且对分区之间的数据分布没有优先级,则使用此分区模式。这是最快的分区模式,因为数据移动被最小化了,所以最好在存储数据的地方处理数据。
- 随机:选择随机分区模式时,可以指定每个分区的大小分区大小设置为绝对大小的分区)或分区数(如果分区大小设置为固定分区数).如果您需要知道分区的数量,但是对分区之间的数据分布没有优先权,那么可以使用这种分区模式。随机分区模式重新分配数据,以创建所需数量(或大小)的分区,因此,它预计比线性分区模式有更大的开销。
- 属性:属性分区模式允许您指定数据在分区之间的分布。类型对输入数据进行分组分区属性,以便每个分区接收一个唯一属性值的数据。在这种情况下,每个示例都必须移动到特定的节点,这将导致大量的网络流量。如果希望对输入数据的确切组执行子流程,则使用此分区模式。请注意,对于不均匀分布的数据,性能是次优的,因为一个分区可能比另一个分区包含更多的示例。
在操作符的每个IOObject输出上创建一个包含所有分区输出的集合。显然,这意味着IOObject集合的大小等于进程中使用的分区的数量。在主(第一个)示例集输出上,您可以在两个行为之间进行选择。的合并输出参数决定了每个分区的输出是应该合并到一个HadoopExampleSet(推荐值和默认值),还是应该创建一个HadoopExampleSet的集合。默认情况下,如果合并输出,如果不同分区生成了具有不同模式的ExampleSets,则该过程将失败。如果您想避免这种情况,请启用解决模式冲突参数——在这种情况下,将交付输出模式的联合,数据间隙(一个分区有值,而另一个分区没有)可以用缺失的值或指定的值填充。请注意,如果合并输出参数未选中时,Radoop会在集合的每个元素上创建一个Hive表。管理大量的Hive表会导致开销,并且可能会达到HiveServer2的限制。因此,我们鼓励您在这个集合中只使用适量的元素,当合并输出没有启用。
类的简单用例SparkRM操作符,为简单起见,仅使用示例数据。
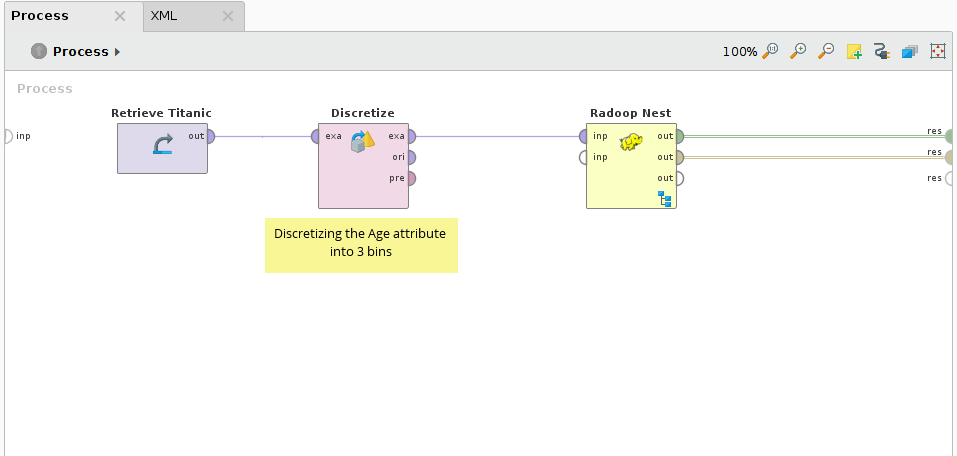
首先检索Titanic样本数据集,并将Age属性离散为3个bin。这将导致Age属性中有4个不同的值:range1[-∞- 26.778];Range2 [26.778 - 53.389];Range3[53.389 -∞]和缺失。请注意,不建议在实际用例中对适合RapidMiner Studio内存的数据(如Titanic数据集)使用RapidMiner Radoop操作符。如果你有大数据,在Nest中使用Radoop的Retrieve(推荐)或Read CSV操作符来访问你的输入。
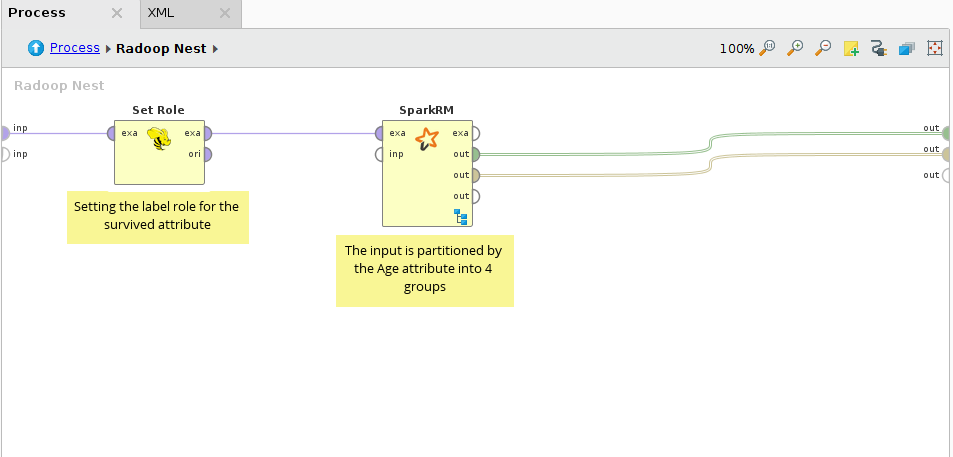
在Radoop Nest中,幸存的属性被指定为标签,数据被连接到SparkRM的第一个(示例集)输入端口。对于SparkRM操作符,设置了属性分区,并将离散化的Age属性设置为分区属性。这将导致4个分区。我们希望为不同的年龄类别建立不同的预测模型。
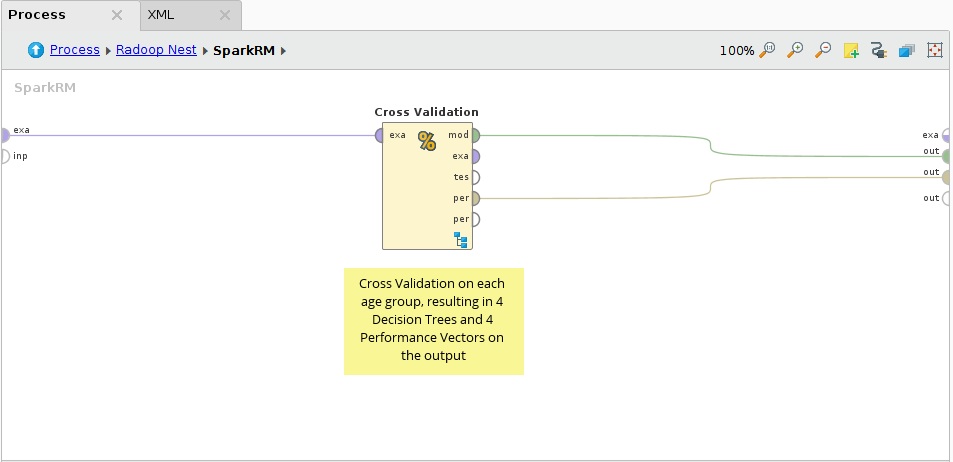
在下推过程中,使用决策树建模器对4个分区并行执行交叉验证。在SparkRM的输出上只使用了两个IOObject输出端口,示例集输出没有连接,因为我们不改变数据集,只是在它(在它的分区上)上构建模型。
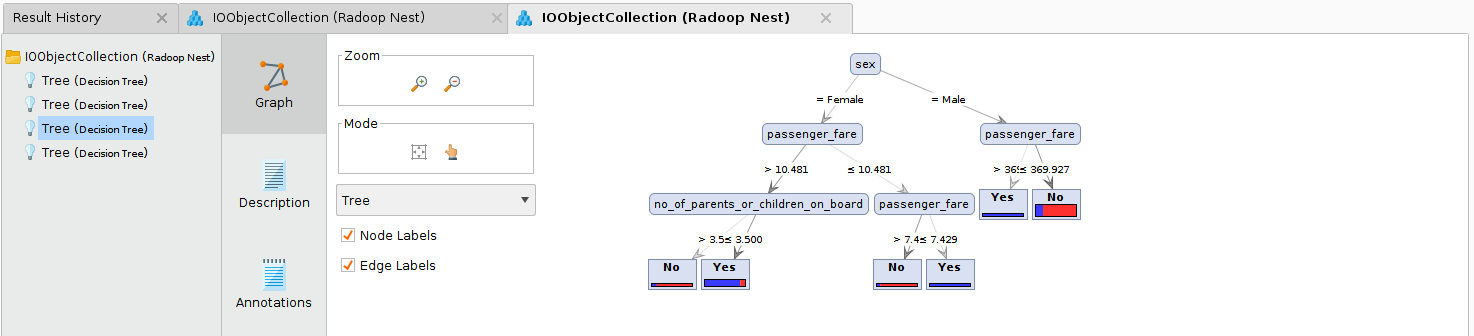
在连接的输出上传递决策树模型集合和性能向量集合。每个集合包含4个元素,可以在Studio的Result视图中进行检查。
高级设置和监控
在运行Spark应用程序时,通常需要指定它将在Hadoop集群上使用的所需内存和核心。Radoop在提交进程时使用自定义资源启发式。对于大多数用例,这与默认设置一起工作得很好,但是调整或关闭启发式也是可能的。更多信息请参考操作人员的帮助面板。
请注意,为了容忍Hadoop集群错误,Spark通常会再次执行一个失败的RapidMiner进程。但这也可能导致不必要的重新运行,以防您的子进程出现进程错误。Radoop仅在出现明显的用户错误或进程设置错误时才会防止这种重新运行。的值为默认的试验次数yarn.resourcemanager.am.max-attempts方法在集群上重写此值spark.yarn.maxAppAttempts高级火花设置.
默认情况下,单流程下推而且SparkRM使用内存监控器是为了在子进程耗尽内存时检测并杀死它。内存监控器可以在属性设置面板。如果禁用该特性,进程可能会长时间停留在RUNNING状态,然后出现内存不足错误而失败。注意:由于已知Spark错误,内存监控服务可能行不通以及SparkRM的属性分区模式。在这种情况下,请关闭内存监视器,正如错误消息所建议的那样。