您正在查看9.4 -版本的RapidMiner Radoop文档点击这里查看最新版本
特定的笔记
对于某些Hadoop发行版,您可能需要使用连接设置对话框。集群修改通常需要SSH连接或访问Hadoop管理工具(例如,Cloudera Manager或Ambari)。您可能需要联系Hadoop管理员来执行集群配置步骤。
对接CDH 5.13快速入门虚拟机
启动并配置快速入门虚拟机
从网站下载Cloudera快速入门虚拟机(版本5.13)Cloudera网站。
将打包好的OVA虚拟机导入到虚拟化环境中(本指南将介绍Virtualbox和VMware)。
强烈建议在虚拟机提供的单机集群上升级到Java 1.8。否则,执行单流程下推和应用模型运营商将会失败。
只有在集群或Cloudera管理服务未启动的情况下,才能执行以下操作。有关完整的升级过程,请阅读Cloudera指南。
升级到Java 1.8:
- 启动虚拟机。
- 最好下载并解压缩JDK 1.8jdk1.8.0_60-
/usr/java/jdk1.8.0_60。 将以下配置行添加到
/etc/default/cloudera-scm-server:出口JAVA_HOME = / usr / java / jdk1.8.0_60- 发射Cloudera表达(或企业试用版)。
打开浏览器,登录到Cloudera经理(
quickstart.cloudera: 7180)使用cloudera / cloudera作为凭证。导航到主机/quickstart.cloudera/配置。在Java主目录字段中,输入/usr/java/jdk1.8.0_60- 的主页上Cloudera经理,(重新)开始Cloudera快速入门集群和Cloudera管理服务也
如果您正在使用Virtualbox,请确保VM已关闭,并设置主网络适配器的类型NAT来您可以将。虚拟机只能在Virtualbox环境中使用此设置。
启动虚拟机,等待引导完成。将出现一个包含一些基本信息的浏览器。
编辑你的当地的
主机文件(在您的主机操作系统上,而不是在VM中)并添加以下行(替换< vm-ip-address >为虚拟机的IP地址):< vm-ip-address > quickstart.cloudera
在RapidMiner Studio中设置连接
点击
 新连接按下并选择
新连接按下并选择 手动添加连接
手动添加连接集Hadoop的用户名来
蜂巢。(作为一种选择,您可以设置这两个Hadoop的用户名和用户名在蜂巢选项卡到您自己的用户。)添加
quickstart.cloudera作为NameNode地址添加
quickstart.cloudera作为资源管理器地址添加
quickstart.cloudera作为Hive服务器地址选择“Cloudera Hadoop (CDH5)”为Hadoop版本
-
关键 价值 dfs.client.use.datanode.hostname真正的(使用时不需要此参数导入Hadoop配置文件选项):
关键 价值 mapreduce.map.java.opts-Xmx256m 选择合适的火花版本(这应该是火花1.6如果您想使用虚拟机的内置Spark程序集jar)并设置装配罐位置到以下值:
本地:/ / / usr / lib /火花/ lib / spark-assembly.jar
连接3.0.1+沙箱虚拟机
启动并配置沙盒虚拟机
从网站下载用于VirtualBox的Hortonworks沙盒虚拟机(版本3.0.1+)Hortonworks网站。
将打包好的OVA虚拟机导入到您的虚拟化环境中(本指南将介绍Virtualbox)。
启动虚拟机。开机后,您必须从启动菜单中选择第一个选项,然后等待启动完成。
登录虚拟机。您可以通过切换到登录控制台(Alt+F5)来实现这一点,或者通过本地主机端口上的SSH更好
2122。重要的是要注意VM上有2个暴露的SSH端口,其中一个属于VM本身(2122),而另一个(2222)属于运行在虚拟机内部的Docker容器。用户名是根,密码为hadoop为两个。- 编辑
/盒/代理/ generate-proxy-deploy-script.sh中包含以下端口tcpPortsHDP数组8025、8030、8050、10020、50010。vi /盒/代理/ generate-proxy-deploy-script.sh找到
tcpPortsHDP变量,保留其他值,添加到哈希表赋值:[8025]=8025 [8030]=8030 [8050]=8050 [10020]=10020 [50010]=50010
- 运行编辑过的generate-proxy-deploy-script.sh通过
/盒/代理/ generate-proxy-deploy-script.sh- 这将重新创建/盒/代理/ proxy-deploy.sh脚本以及配置文件/盒/代理/ conf.d和/盒/代理/ conf.stream.d,从而公开添加到的附加端口
tcpPortsHDP上一步中的哈希表。
- 这将重新创建/盒/代理/ proxy-deploy.sh脚本以及配置文件/盒/代理/ conf.d和/盒/代理/ conf.stream.d,从而公开添加到的附加端口
- 运行/盒/代理/ proxy-deploy.sh脚本通过
/盒/代理/ proxy-deploy.sh- 运行
码头工人ps命令,将显示一个名为sandbox-proxy以及它暴露的港口。中插入的值tcpPortsHDP输出中应该显示Hashtable,如下所示0.0.0.0:10020 - > 10020 / tcp。
- 运行
这些更改只确保Docker容器的引用端口可以在VM的相应端口上访问。由于虚拟机的网络适配器附加到NAT,因此无法从本地计算机访问这些端口。要使它们可用,您必须将下面列出的端口转发规则添加到VM。在VirtualBox中,您可以在机/设置/网络/适配器1/先进的/端口转发。
名字 协议 主机IP 主机端口 客人的IP 客人港口 resourcetracker TCP 127.0.0.1 8025 8025 乐鱼体育安装resourcescheduler TCP 127.0.0.1 8030 8030 resoucemanager TCP 127.0.0.1 8050 8050 jobhistory TCP 127.0.0.1 10020 10020 datanode TCP 127.0.0.1 50010 50010 编辑你的当地的
主机文件(在您的主机操作系统上,而不是在虚拟机中),添加sandbox.hortonworks.com和sandbox-hdp.hortonworks.com到本地主机条目。最后它看起来应该是这样的:localhost sandboxhdp.hortonworks.com重置Ambari访问。使用SSH客户端登录Localhost作为根用户,这次使用端口
2222!(以OS X、Linux操作系统为例SSH root@localhost -p 2222,密码:hadoop)- (第一次登录时,你必须设置一个新的root密码,这样做并记住它。)
- 运行
ambari-admin-password-reset以root用户。 - 为Ambari提供一个新的管理员密码。
- 运行
ambari-agent重启。
打开Ambari网站:
http://sandbox.hortonworks.com:8080- 登录与
管理以及您在上一步中选择的密码。 - 导航到纱/配置/内存配置页面。
- 编辑内存节点设置为至少7gb,单击“覆盖”。
- 用户将被提示创建一个新的“YARN配置组”,输入一个新的名称。
- 在“Save Configuration Group”对话框中,单击管理主机按钮。
- 在“Manage YARN Configuration Groups”页面中,将“Default”组中的节点添加到“YARN Configuration group”名称步骤中创建的组中。
- “警告”对话框将打开,请求添加注释单击保存按钮。
- “依赖配置”对话框将打开,Ambari将提供自动修改一些相关属性的建议。如果是,那就停止
tez.runtime.io.sort.mb以保持其原有价值。单击好吧按钮。- 安巴里可能会打开一个“配置”页面,提出一些建议。请进行相应的检查,但这超出了本文的范围,因此只需单击即可继续做下去。
- 导航到蜂巢/配置/先进的配置页面。
在自定义hiveserver2-site部分。的
hive.security.authorization.sqlstd.confwhitelist.append需要通过添加属性…并设置为如下格式(不能包含空格):radoop \ .operation \ .id | mapred \ .job \ . name |蜂巢\ .warehouse \ .subdir \ .inherit \ .perms |蜂巢\ .exec \ .max \ .dynamic \ .partitions |蜂巢\ .exec \ .max \ .dynamic \ .partitions \ .pernode |火花\ .app \ . name |蜂巢\ .remove \ .orderby \在\ .subquery- 保存配置并重新启动所有受影响的服务。更多关于
hive.security.authorization.sqlstd.confwhitelist.append可以在Hadoop安全/配置Apache Hive SQL标准授权部分。
- 登录与
在RapidMiner Studio中设置连接
点击
新连接按下并选择 从集群管理器导入选项,直接从从Ambari检索到的配置中创建连接。
从集群管理器导入选项,直接从从Ambari检索到的配置中创建连接。- 在从集群管理器导入连接对话框中输入
- 集群管理器URL:
http://sandbox-hdp.hortonworks.com:8080 - 用户名:
管理 - 密码“Reset Amabari”步骤中使用的密码。
- 集群管理器URL:
点击导入配置
- Hadoop配置导入对话框将打开
- 如果成功,点击下一个按钮,连接设置对话框将打开。
- 如果失败,点击回来点击并查看上述步骤和日志以解决问题。
在连接设置对话框,当下一个按钮从上面的步骤单击。
连接名可以保持默认或由用户更改。
- 全球选项卡
- Hadoop版本应该是
Hortonworks HDP 3.x - 集Hadoop的用户名来
hadoop。
- Hadoop版本应该是
- Hadoop选项卡
- NameNode地址应该是
sandbox-hdp.hortonworks.com - NameNode港口应该是
8020 - 资源管理器地址应该是
sandbox-hdp.hortonworks.com - 资源管理器端口应该是
8050 - JobHistory服务器地址应该是
sandbox-hdp.hortonworks.com - JobHistory服务器端口应该是
10020 -
关键 价值 dfs.client.use.datanode.hostname真正的(使用时不需要此参数导入Hadoop配置文件选项):
关键 价值 mapreduce.map.java.opts-Xmx256m
- NameNode地址应该是
- 火花选项卡
- 火花版本选择
Spark 2.3 (HDP) - 检查使用默认的Spark路径
- 火花版本选择
- 蜂巢选项卡
- 蜂巢版应该是
HiveServer3 (Hive 3或更新版本) - Hive高可用性应该检查一下
- 动物园管理员法定人数应该是
sandbox-hdp.hortonworks.com: 2181 - 管理员名称空间应该是
hiverserver2 - 数据库名称应该是
默认的 - JDBC URL后缀应该是空的
- 用户名应该是
蜂巢 - 密码应该是空的
- udf是手动安装的和为udf使用自定义数据库都是未经检查的
- Hive on Spark/Tez容器重用应该检查一下
- 蜂巢版应该是
点击好吧按钮时,连接设置对话框将关闭
- 用户可以在onn上测试上面创建的连接管理Radoop连接页面选择创建的连接并单击快速测试和
 完整的测试……按钮。
完整的测试……按钮。
如果在测试过程中出现错误,请确认必要的组件已正确启动http://localhost:8080/#/main/hosts/sandbox-hdp.hortonworks.com/summary。
强烈建议使用![]() 新连接/
新连接/![]() 从集群管理器导入选项,直接从从Cloudera Manager检索到的配置中创建连接。如果您没有可以访问配置的Cloudera Manager帐户,管理员应该可以下载客户端配置。使用客户端配置文件,选择
从集群管理器导入选项,直接从从Cloudera Manager检索到的配置中创建连接。如果您没有可以访问配置的Cloudera Manager帐户,管理员应该可以下载客户端配置。使用客户端配置文件,选择![]() 新连接/
新连接/![]() 导入Hadoop配置文件从这些文件创建连接。
导入Hadoop配置文件从这些文件创建连接。
如果在集群上启用了安全性,请确保进行了检查配置Apache哨兵授权部分Hadoop的安全一章。
配置火花
如果您使用的是Spark 1.6版本,您可能需要选择Spark 1.6 (CDH)查看最近的cdh5。x Cloudera Hadoop版本和火花1.6较老的cdh5。x版本。选择其中任何一个,然后运行火花作业测试(只启用此测试![]() 完整的测试……/
完整的测试……/![]() 自定义…),自动为您检测合适的版本。请选择此测试推荐的设置。
自定义…),自动为您检测合适的版本。请选择此测试推荐的设置。
使用任何其他Spark版本都应该很简单。
下面介绍了HDP 2.5.0、2.6.0、3.0和3.1的设置。其他HDP版本的设置应该类似。
配置集群
如果集群上的Hive命令有限制(例如,基于SQL标准的Hive授权),那么必须显式地启用通过HiveServer2更改某些属性。如果在RapidMiner Radoop中运行完整测试时得到以下错误信息,则需要这样做:不能在运行时修改radoop.operation.id。在这种情况下,必须在Ambari接口上添加一个属性来解决这个问题。
- 登录Ambari界面。
- 导航到蜂巢/配置/先进的配置页面
- 添加
hive.security.authorization.sqlstd.confwhitelist.append设置为两者的新属性自定义hive-site和自定义hiveserver2-site。该值应该如下所示(不能包含空格):radoop \ .operation \ .id | mapred \ .job \ . name |蜂巢\ .warehouse \ .subdir \ .inherit \ .perms |蜂巢\ .exec \ .max \ .dynamic \ .partitions |蜂巢\ .exec \ .max \ .dynamic \ .partitions \ .pernode |火花\ .app \ . name
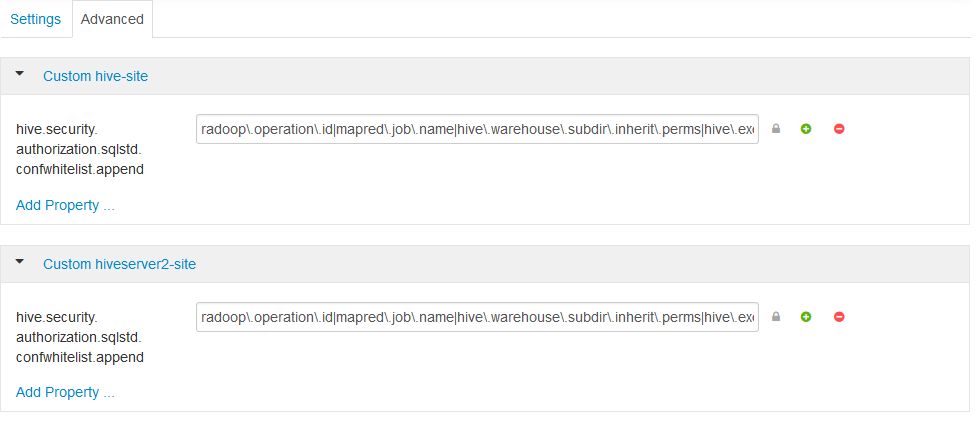
- 保存配置并重新启动建议的服务。
有关更详细的解释,请参阅Hadoop的安全部分。
要在RapidMiner Radoop中启用Spark操作符,请在连接设置对话框:
选择合适的火花版本选项中的火花设置。如果Spark与Ambari一起安装,则火花版本取决于集群的HDP版本。
黄芪丹参滴丸版本 Spark组件JAR位置 里 Spark 2.3 (HDP) 3.0.x Spark 2.3 (HDP) 伴有 Spark 1.6或Spark 2.1 / Spark 2.2 2.5.x Spark 1.6或Spark 2.0 设置装配罐位置/Spark归档路径指向集群上的Spark位置。下表包含根据HDP版本的默认本地位置。如果指定的路径似乎不起作用,请咨询Hadoop管理员。
黄芪丹参滴丸版本 火花1。x汇编JAR位置 火花2。X归档路径 里 本地:/ / / usr /黄芪丹参滴丸/电流/ spark2-client /罐/3.0.x 本地:/ / / usr /黄芪丹参滴丸/电流/ spark2-client /罐/伴有 本地:/ / / usr /黄芪丹参滴丸/电流/ spark-client / lib / spark-hdp-assembly.jar本地:/ / / usr /黄芪丹参滴丸/电流/ spark2-client /罐/2.5.x 本地:/ / / usr /黄芪丹参滴丸/电流/ spark-client / lib / spark-hdp-assembly.jar
安全注意事项
如果在连接完全测试期间收到权限错误,请验证:
- 的
/用户/ < hadoop_username >目录在HDFS上存在,属于。(如果Hadoop用户名设置为空,则使用客户端操作系统用户名。) 具有写权限 / user /历史目录。
基于SQL标准的Hive授权可能要求运行HiveServer2的用户拥有加载到Hive中的文件和目录。这可能会破坏RapidMiner Radoop的正常运行。如果出现权限错误,请咨询Hadoop管理员。
使用Radoop Proxy连接到Azure HDInsight 3.6集群
RapidMiner Radoop支持Azure HDInsight的3.6版本,这是一个基于云的Hadoop服务,建立在Hortonworks数据平台(HDP)发行版上。如果RapidMiner Radoop不在Azure网络中运行,则有几个网络设置选项。像这样的解决方案Azure ExpressRoute或者VPN可以简化设置。但是,如果这些选项不可用,可以使用Radoop Proxy访问HDInsight集群,它协调RapidMiner Studio和集群资源之间的所有通信。乐鱼体育安装由于这种设置是最复杂的,因此本指南假设了这种场景,因此可以随意跳过不需要的步骤,因为网络设置更简单。
对于一个正确的网络设置,一个RapidMiner Server实例(带有Radoop代理应该安装在与集群节点位于同一虚拟网络中的另一台机器上。下面的指南提供了建立到HDInsight集群的代理连接的必要步骤。
启动HDInsight集群
如果您已经在Azure网络中运行了HDInsight集群,请完全跳过这些步骤。
新建一个虚拟网络用于在集群设置期间创建的所有网络资源。乐鱼体育安装默认的地址空间和子网地址范围可能适合这个目的。使用相同的资源组在整个集群设置过乐鱼体育安装程中创建的所有资源。
使用自定义(大小,设置,应用程序)选择而不是快速创建用于创建集群。选择火花集群类型Linux操作系统,以及Radoop支持的最新Spark版本,即Spark 2.2.0 (HDI 3.6)写这篇文章的时候。填写所有必需的登录凭据字段。选择前面定义的资源组。
选择主存储类型集群的。您还可以指定其他存储帐户。
- Azure存储:提供新的或已经存在的存储账户和一个默认的容器名字您可以根据需要连接到任意多个Azure存储帐户。
- 数据湖存储:提供数据湖存储帐号。确保根路径存在,并且关联的服务主体具有访问所选数据湖存储和路径的足够特权。请注意,Service主体也可以在其他集群设置中重用。为此,建议保存证书文件和证书密码供将来参考。一旦选择了服务主体,就可以通过这个服务主体对象配置任何数据湖存储的访问权限。
配置集群规模随你的便。
在高级设置选项卡,选择前面创建的虚拟网络和子网。
完成向导的所有步骤后,创建集群。启动后,请查找主节点的私有ip和私有域名。您需要将这些文件复制到本地机器上。这一步是必需的,因为一些域名解析需要发生在客户端(RapidMiner Studio)。最简单的方法是从一个集群节点复制它。导航到HDInsight集群的仪表板,然后选择SSH +集群登录选择。中选择任何项目主机名选择器。在Linux和Mac系统上,您可以使用出现在选择器下面的ssh命令。在Windows系统上,您必须从命令中提取主机名和用户名,然后使用腻子连接主机。密码为您在步骤2中提供的密码。连接成功后,查看远程主机的/etc/hosts文件的内容,例如执行以下命令:
猫/ etc / hosts。复制所有具有长生成的主机名的条目。将它们粘贴到主机你的档案本地机器,可在下列地点索龋- Windows系统:Windows\system32\drivers\etc\hosts
- Linux和Mac系统:/etc/hosts

启动RapidMiner Server和Radoop Proxy
在Azure中创建一个新的RapidMiner服务器虚拟机。为此,您需要选择“创建资源”选项并在市场中搜索RapidMiner服务器。选择BYOL与您的Studio版本最匹配的版本。新闻创建然后开始配置虚拟机。根据您的喜好提供基本设置,但请确保使用先前配置的设置资源组同样的位置至于你的集群。点击好吧,然后选择一个至少有10GB RAM的虚拟机大小。配置可选特性。这是至关重要的虚拟网络和子网在网络设置为集群使用的设置。所有其他设置可以保持不变。检查摘要,然后单击创建。
虚拟机启动后,您仍然需要等待几分钟来启动RapidMiner Server。验证这一点的最简单方法是在浏览器中打开(VM的公共IP地址):8080。一旦页面加载,你就可以登录了管理用户名和Azure中虚拟机的名称作为密码。系统将立即要求您输入有效的许可密钥。对于这个目的,免费许可证是完全可以的。如果您的许可证被接受,您可以关闭此窗口,您将不再需要它。
在RapidMiner Studio中设置连接
首先,为新安装的Radoop代理(描述)创建一个Radoop代理连接在这里所需的属性有:
| 场 | 价值 |
|---|---|
| Radoop代理服务器主机 | 提供MySQL服务器实例的IP地址。 |
| Radoop代理服务器端口 | 的价值radoop_proxy_port在使用的RapidMiner服务器安装配置XML (1081默认情况下)。 |
| RapidMiner服务器用户名 | 管理(默认) |
| RapidMiner服务器密码 | Azure代理虚拟机的名称(默认) |
| 使用SSL | 假(默认) |
为设置一个新的Radoop连接对于Azure HDInsight 3.6集群,我们强烈建议选择![]() 从集群管理器导入选项,因为它提供了迄今为止使连接正常工作的最简单方法。这介绍集群管理器的导入流程。的集群管理器URL应该是Ambari接口网页的基础URL(例如:
从集群管理器导入选项,因为它提供了迄今为止使连接正常工作的最简单方法。这介绍集群管理器的导入流程。的集群管理器URL应该是Ambari接口网页的基础URL(例如:https://radoopcluster.azurehdinsight.net)。您可以通过点击轻松访问它洋麻的观点在集群仪表板上。
导入连接后,将自动填写所需的大部分设置。在大多数情况下,只需手动提供以下属性:
| 场 | 价值 |
|---|---|
| Hadoop高级参数 | 禁用以下属性:io.compression.codec.lzo.class和io.compression.codecs |
| Hive服务器地址 | 只有当您不使用ZooKeeper服务发现时,才需要这样做(Hive高可用性未检查)。可在Ambari界面(Hive / HiveServer2)。在大多数情况下,它与NameNode地址。 |
| Radoop代理连接 | 应该选择前面创建的Radoop代理连接。 |
| 火花版本 | 选择与集群上安装的Spark相匹配的版本,即火花2.2如果您按照上面的步骤安装HDInsight。 |
| Spark Archive(或lib)路径 | 为火花2.2(对于HDInsight 3.6),默认值是(本地:/ / / usr /黄芪丹参滴丸/电流/ spark2-client / jar)。除非使用不同的Spark版本,否则您可以离开使用默认的Spark路径复选框选中。 |
| 高级火花参数 | 创建spark.yarn.appMasterEnv.PYSPARK_PYTHON属性,值为/usr/bin/anaconda/bin/python。 |
您还需要配置存储凭据,这由存储凭证设置部分。如果要连接到高级集群,则需要按照连接到高级集群部分。完成这些步骤后,可以单击好吧在连接设置对话框,并保存连接。
RapidMiner Radoop客户端必须能够解析主节点的主机名。按照步骤6的启动HDInsight集群将这些主机名添加到操作系统的hosts文件中。
存储凭证设置
一个HDInsight集群可以有更多的存储实例,甚至可以有不同的存储类型(Azure存储和数据湖存储)。要访问它们,必须在中提供相关凭证Hadoop高级参数表格下面几节阐明了所需的凭证类型,以及如何获得它们。
至关重要的是主存储器被提供。
您可以将多个Azure存储连接到HDInsight集群,前提是在集群设置期间指定了任何其他存储。所有这些都有访问键,可以在访问键选项卡上的存储仪表板。要启用对Azure存储的访问,请将此密钥作为Hadoop高级参数:
| 关键 | 价值 |
|---|---|
fs.azure.account.key。< storage_name > .blob.core.windows.net |
存储访问键 |
如上所述,一个活动目录服务主体对象可以被附加到集群。这控制了对数据湖存储的访问权限。显然,只有一个数据湖存储可以充当主存储。为了使Radoop能够通过此主体访问数据湖存储,请执行以下操作Hadoop高级参数必须指定:
| 关键 | 价值 |
|---|---|
dfs.adls.oauth2.access.token.provider.type |
ClientCredential |
dfs.adls.oauth2.refresh.url |
OAuth 2.0令牌端点地址 |
dfs.adls.oauth2.client.id |
服务主体应用程序ID |
dfs.adls.oauth2.credential |
服务主体访问密钥 |
你可以得到所有这些值Azure Active Directory仪表板(可在主Azure门户的服务列表中获得)。点击应用程序注册然后在仪表板上查找所需的值,如下所示:
- 为OAuth 2.0令牌端点地址,去端点,并复制的值OAuth 2.0令牌端点。
- 在应用程序注册页,选择与HDInsight集群相关联的服务主体,并提供的值应用程序ID作为服务主体应用程序ID。
- 点击键。通过输入名称和到期日期生成新密钥,并替换的值服务主体访问密钥使用生成的密码。
最后,转到HDInsight集群主页面,并单击数据湖存储访问在菜单上。提供…的价值服务主体对象ID作为Hadoop的用户名。
连接到高级集群(启用Kerberos)
如果您已经设置或拥有高级HDInsight集群(需要订阅),则需要对基于kerberos的身份验证进行一些额外的连接设置。
- 配置Kerberos认证节介绍与kerberos相关的一般设置。
- 对于所有基于Hortonworks分布的集群,您还必须应用Hive设置(
hive.security.authorization.sqlstd.confwhitelist.append)所述本节。请注意,需要重新启动Hive服务。 - 我们强烈建议使用从集群管理器导入选项,用于创建到支持kerberos的集群的Radoop连接。的导入过程包含一些必要的更改Hadoop高级参数它们是连接按预期工作所必需的。
有多个选项可以连接到EMR集群
以下步骤遵循Radoop Proxy的建议,但您也可以在下面找到其他两个远程方法的附加步骤的分步指南。对于直接访问设置,请遵循Radoop Proxy指南,但跳过描述Radoop Proxy本身设置的部分。
使用Radoop Proxy连接到防火墙EMR集群
以下步骤将指导您启动和配置EMR集群,并通过在EMR集群的主节点上运行的RapidMiner Radoop代理从RapidMiner Radoop访问它。
如果您还没有运行EMR集群,那么可以使用AWS Console上的高级选项来创建EMR集群。选择一个5.倍版本EMR释放。确保Hadoop,蜂巢和火花在“软件配置”步骤中选择进行安装。在AWS Console上完成其余的配置步骤,然后启动集群。
SSH到主节点(一旦它的状态变为
运行或等待在您的EMR集群的Summary选项卡上可以找到SSH指令。注意<主公共DNS名称>,这将在稍后的RapidMiner Studio中的Radoop Proxy配置中用到。(如:ec2 - 35 - 85 - 2 - 17. -计算- 1. amazonaws.example.com)获取Master节点的内部IP地址(例如:
10.1.2.3)通过主机名我命令,并将其记录下来,因为这将用于Radoop连接。(私有IP和DNS信息也可以从AWS控制台的EMR集群详细信息页面的硬件部分查看“EC2实例”)执行以下命令在集群上为Radoop设置Spark。对于Spark 2。最好的做法是从主节点的预安装位置将压缩后的Spark jar文件上传到HDFS。(这是至关重要的,因为EMR通常只将相关库安装到主节点的文件系统上,而工作节点也依赖于它们)所有这些都可以通过在EMR主节点上发出以下命令轻松完成:
#设置Spark 2*库从默认安装位置cd /usr/lib/spark zip / tmp / spark-jars.zip——junk-paths recurse-paths。/ jar hdfs dfs mkdir - p / user /火花hdfs dfs——/ tmp / spark-jars.zip / user /火花PySpark机库到hdfs hdfs dfs——#副本。/ python / lib / py4j-src.zip / user / hdfs dfs——火花。/ python / lib / pyspark.zip / user /火花SparkR机库到hdfs hdfs dfs——#副本。/ R / lib / sparkr.zip / user /火花#列出所有文件放在hdfs hdfs dfs / user /火花的目录-ls /user/spark如果一切正常,输出应该非常类似于:
[hadoop@ip-172-31-18-147 spark]$ hdfs dfs -ls /user/spark/spark .zip发现4个项目-rw-r——r——1 hadoop spark 74096 2019-07-25 17:47 /user/spark/py4j-src.zip -rw-r——r——1 hadoop spark 482687 2019-07-25 17:48 /user/spark/pyspark.zip -rw-r——r——1 hadoop spark 180421304 2019-07-25 17:47 /user/spark/spark-jars.zip -rw-r——r——1 hadoop spark 698696 2019-07-25 17:48 /user/spark/spark /spark .zip
的说明独立Radoop代理部分。配置完成后启动Radoop Proxy。
启动RapidMiner Studio和创建一个新的Radoop代理连接。使用
(从步骤2开始)作为Radoop代理服务器主机。测试代理连接测试连接按钮。 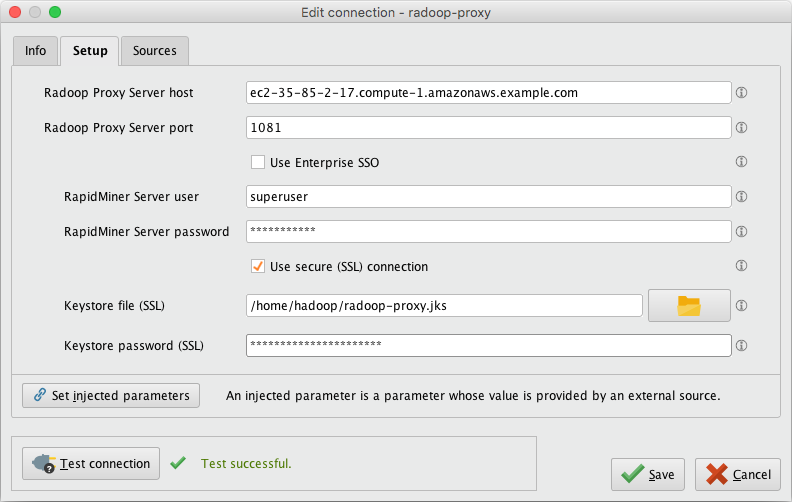
在RapidMiner Studio中创建一个新的Radoop连接使用以下值(您可以根据需要提供其他配置参数)。高级Radoop用户也可以选择导入连接模板下面其中包括该表中列出的所有必需设置。
财产 价值 Hadoop版本 Amazon Elastic MapReduce (EMR) 5.x Hadoop的用户名 hadoop NameNode地址 <步骤3中的主节点内部IP地址>(例如: 10.1.2.3)NameNode港口 8020 资源管理器地址 <步骤3中的主节点内部IP地址>(例如: 10.1.2.3)资源管理器端口 8032 JobHistory服务器地址 <步骤3中的主节点内部IP地址>(例如: 10.1.2.3)Hadoop高级参数 添加键/值 dfs.client.use.datanode.hostname的价值假火花版本 对应的Spark版本(例如: 火花2.3.1 +)使用自定义PySpark归档 检查 自定义PySpark归档路径 添加两个条目 hdfs: / / / user / / py4j-src.zip火花和hdfs: / / / user / / pyspark.zip火花使用自定义SparkR存档 检查 自定义SparkR存档路径 hdfs: / / / user / / sparkr.zip火花Hive服务器地址 <步骤3中的主节点内部IP地址>(例如: 10.1.2.3)蜂巢的用户名 蜂巢 使用Radoop代理 检查 Radoop代理连接 <选择在步骤6中创建的代理> 请注意请考虑按照讨论的方法微调Spark内存设置在这里。

<?xml version="1.0" encoding="UTF-8"? Amazon EMR连接示例 9.4.0 <主节点内部IP地址如10.1.2.3> < namendeaddress ><主节点内部IP地址如10.1.2.3>< jobHistoryServerAddress><主节点内部IP地址如10.1.2.3> <主节点内部IP地址如10.1.2.3>10.1.2.3> T default 10000 8032 8020 10020 < hivehighhahaavailability >F hadoop-emr-5。x F T F T auth F SPARK_23_1 T T hdfs:///user/spark/pyspark.zip,hdfs:///user/spark/ spark/py4j-src.zip hdfs:// user/spark/spark .zip hdfs:// user/spark/spark .zip 动态 30 dfs.client.use.datanode. datanode. confhostname false T < advancedhivessettings /> spark.driver。extraJavaOptions -XX:+PrintGC -XX:+PrintGCDateStamps T spark.driver。内存 2000 T spark.executor。extraJavaOptions -XX:+PrintGC -XX:+PrintGCDateStamps T spark.executor。内存 2000Mb T spark。logConf true T hive hive hive2 F hive_0.13.0 yarn * F T - 保存Radoop连接并执行快速/完整的测试相应的行动。
一个不同的Hadoop的用户名可以使用,但请检查用户名是否已创建,并对?具有适当的权限和所有权/用户/ <用户名>HDFS上的目录HDFS DFS -ls /user。
SOCKS代理是连接到EMR集群的另一个选项。看到网络设置节,获取有关启动SOCKS代理和SSH隧道的信息。请打开SSH隧道和SOCKS代理。
在RapidMiner Studio中设置连接
选择Amazon Elastic MapReduce (EMR) 5.x作为Hadoop版本。
设置以下地址:
- NameNode地址:
(例如: 10.1.2.3) - 资源管理器地址:
10.1.2.3) - JobHistory服务器地址:
(例如: 10.1.2.3) - Hive Server地址:
本地主机
- NameNode地址:
根据需要设置端口
- 集蜂巢港口至1235年(如网络设置)
添加以下内容Hadoop高级参数键值对(如网络设置):
关键 价值 dfs.client.use.legacy.blockreader真正的hadoop.rpc.socket.factory.class.defaultorg.apache.hadoop.net.SocksSocketFactoryhadoop.socks.serverlocalhost: 1234保存Radoop连接并执行快速/完整的测试相应的行动。
EMR VPN是连接到EMR集群的另一种选择。这将需要使用VPN软件设置一个专用的EC2实例。
建立VPN
如果用户已经为EMR集群建立了VPN,则可以跳过本节。但是用户仍然需要注意VPN的IP地址和DNS名称,并确保VPN连接到EMR集群的VPC和子网。
当集群处于
运行或等待状态时,请注意EC2实例的私有ip和私有域名应该可用。使用与EMR集群在同一VPC中的EC2实例启动VPN服务器。
从桌面连接到VPN
- 检查是否设置了正确的路由(例如:
172.30.0.0/16)
- 检查是否设置了正确的路由(例如:
启用VPN到EMR集群的网络流量
- 在EMR集群详细信息页面上打开主安全组设置页面(稍后打开从安全组设置页面)
- 在入站规则中添加一条新规则,并启用“所有来自VPC网络的流量”(例如:
172.30.0.0/16) - 在EMR集群的Master和Slave安全组上都进行此设置吗
可选:设置本地hosts文件(如果您想使用主机/DNS名称而不是IP地址)
- 在硬件部分的EMR集群详细信息页面中,检查“EC2实例”并获取私有IP和DNS。
- 将节点的主机名(DNS)和IP地址添加到本地主机文件中(例如:
172.30.1.209 ip - 172 - 30 - 1 - 209. - ec2.local)
在RapidMiner Studio中设置Radoop连接以使用VPN
当VPN服务器已经建立时建立VPN上面的指令或由一些外部实体Radoop连接可以创建。使用中描述的步骤使用Radoop Proxy连接到防火墙EMR集群部分跳过了Radoop Proxy本身的设置要求。
已弃用发行版的注意事项
Radoop支持MapR 5.x/6。x用于RapidMiner Studio和RapidMiner Server。请注意,服务器上支持MapR需要RapidMiner Server 8.1或更高版本。
设置集群机器
- 确保DNS和反向DNS解析在所有集群机器上都有效,即使它是单个节点集群。要实现这一点,您不妨设置DNS服务或手动编辑
设置每个节点上的文件。
设置客户端机器
工作室和服务器作业代理必须在安装了MapR 5的主机上运行。X或6。安装并连接X客户端。
- 根据MapR集群版本的不同,用户需要按照说明进行安装MapR 5.倍Client或者是MapR 6.倍Client。确保选择与集群对应的版本。
- 请设置以下系统环境变量:
- MAPR_HOME-这是MapR客户端的路径,在默认安装中也可以是
/ opt / mapr或C: \ \ mapr选择 - HADOOP_HOME-这是客户端MapR Hadoop文件的路径,通常是
$ {MAPR_HOME} / hadoop / hadoop-x.y.z(与x.y.z作为hadoop的版本号),这是在Windows上运行Radoop所必需的,如果设置不正确,用户可能会看到错误消息错误跑龙套。Shell:无法在hadoop二进制路径中找到winutils binary在建立到MapR集群的连接时 - MAPR_SUBNETS—system环境变量包含MapR集群的内部子网。更多关于MAPR_SUBNETS发现在这里
- 添加
$ {HADOOP_HOME} \ bin到系统范围的环境变量路径,如果设置不正确,用户可能会看到错误消息java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO Windows.access0美元(Ljava / lang / String; I) Z在建立到MapR集群的连接时。
- MAPR_HOME-这是MapR客户端的路径,在默认安装中也可以是
- 仔细检查你的
$ {MAPR_HOME} / conf / mapr-cluster.conf文件。检查列出的所有地址是否可以从客户端计算机访问。 - 不安全集群的用户设置
- 在安全配置的OS X或Linux上,确保该用户在所有集群节点上可用。这可以在集群端通过创建一个UID与客户端匹配的新用户来完成。方法可以实现这一点
adduserunix命令。 - 在Windows上,编辑
$ {MAPR_HOME} / hadoop / hadoop-x.y.z / etc / hadoop / core-site.xml配置用于访问集群的集群用户的UID、GID和用户名,请参见Windows下配置MapR客户端用户。这对于mapr5都是必需的。x和MapR 6。x客户机。
- 在安全配置的OS X或Linux上,确保该用户在所有集群节点上可用。这可以在集群端通过创建一个UID与客户端匹配的新用户来完成。方法可以实现这一点
- 要确认客户端机器已连接,用户应该能够从命令行执行以下命令并返回有效的结果。这两个
纱和hadoop命令应该是可访问的,因为添加了$ HADOOP_HOME / bin到系统范围的环境路径。看到MapR你的第一个Hadoop工作获取详细信息。(如果集群是安全的,则通过maprlogin可能需要在运行命令之前。)Hadoop fs -ls /应该返回一个文件列表吗yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0-mapr-1803.jar将在集群上运行hadoop提供的mapreduce作业示例来计算Pi。对于结果,请检查作业历史记录服务器中的应用程序日志。
如果你的HiveServer2实例是由MapR Security保护的,你需要为Hive访问做额外的设置。如果不是,可以跳过此步骤。复制罐子根据MapR JDBC连接文档到主机上的公共目录。应该可以从MapR 5.x/6复制这些jar文件。. x集群机器,Hive通常安装在
$ {MAPR_HOME} /蜂巢/蜂巢——<版本> / lib目录中。请参阅下面的示例列表。请注意,这些文件在您的环境中可能有所不同。
| 文件名称 |
|---|
| hive-exec-2.1.1-mapr——<版本> . jar |
| hive-jdbc-2.1.1-mapr——<版本> . jar |
| hive-metastore-2.1.1-mapr——<版本> . jar |
| hive-service-2.1.1-mapr——<版本> . jar |
| hive-shims-2.1.1-mapr——<版本> . jar |
| httpclient-4.4.jar |
| httpcore-4.4.jar |
| libfb303-0.9.3.jar |
| libthrift-0.9.3.jar |
| log4j-1.2.17.jar |
| 在mapr6的情况下。您可能还需要: |
| log4j-api-2.4.1.jar |
| log4j-core-2.4.1.jar |
Radoop连接设置
在安全集群的情况下,当通过Radoop连接到安全集群时,MapR票证必须始终可用。指maprlogin有关进一步信息的命令文档。您必须为所有服务器地址输入可访问的主机名(例如:蜂巢的地址)。
点击![]() 新连接按下并选择
新连接按下并选择![]() 手动添加连接
手动添加连接
全局选项卡
选择MapR 5.倍或MapR 6.倍为Hadoop版本。
- 请核实MapR客户端主页和MapR子网因为它们显示在对话框中,取自系统环境。
选择或输入MapR集群名称MapR集群。这个下拉是从
$ {MAPR_HOME} / conf / mapr-clusters.conf文件。如果这里没有列出集群名称,则可能是在设置客户机机器部分中没有正确设置MapR客户机。如果Hadoop实例是由MapR安全保护的,请选择启用MapR安全。
Hadoop选项卡
输入资源管理器地址和JobHistory服务器地址字段。
查看默认端口设置JobHistory服务器端口字段。
火花选项卡
选择火花版本根据集群上安装的Spark版本进行配置。如果没有安装,请选择没有一个。有关更多信息,请参见在MapR文档中在Yarn上安装Spark有关集群安装说明。
你可以使用默认的Spark路径,以提供实际路径Spark Archive(或lib)路径文本框。
- 基于所选的Hadoop版本,Spark Archive(或lib)路径字段默认为:
- MapR 5.倍–
本地:/ / / opt / mapr /火花/ spark-2.1.0 / jar - MapR 6.倍–
本地:/ / / opt / mapr /火花/ spark-2.2.0 / jar
- MapR 5.倍–
- 该路径必须在集群上可访问,并且包含spark工件。
- 基于所选的Hadoop版本,Spark Archive(或lib)路径字段默认为:
提供Spark资源分配策略根据您在集群上的Spark设置。
- Spark资源分配策略默认为动态资源分配。如果集群没有为此配置,Spark测试将超时并记录条目
InvalidAuxServiceException: auxService:spark_shuffle不存在会出现在对应Spark作业的日志中。在这种情况下,将集群更改为enable动态资源分配看到MapR -在Apache Spark中启用动态分配或者改成不同的资源分配策略在Radoop连接(例如到静态、默认配置)。
- Spark资源分配策略默认为动态资源分配。如果集群没有为此配置,Spark测试将超时并记录条目
在Windows操作系统下,添加以下内容高级火花参数条目。这里我们假设MAPR_HOME美元在集群上是
/ opt / mapr,如果不是这种情况,请更改值。关键 价值 spark.driver.extraClassPath/ opt / mapr / hadoop / hadoop-2.7.0 /分享/ hadoop mapreduce / *- 如果正在连接的MapR集群已启用高可用性。你还需要对
$ {HADOOP_HOME} / etc / hadoop / yarn-site.xml到高级火花参数。
对于每一个财产元素中存在的$ {HADOOP_HOME} / etc / hadoop / yarn-site.xml做到以下几点:- 新建一个高级火花参数行
- 复制
名字元素值设置为关键字段添加spark.hadoop。值 - 复制
价值元素价值场 - 确保新行被标记为启用
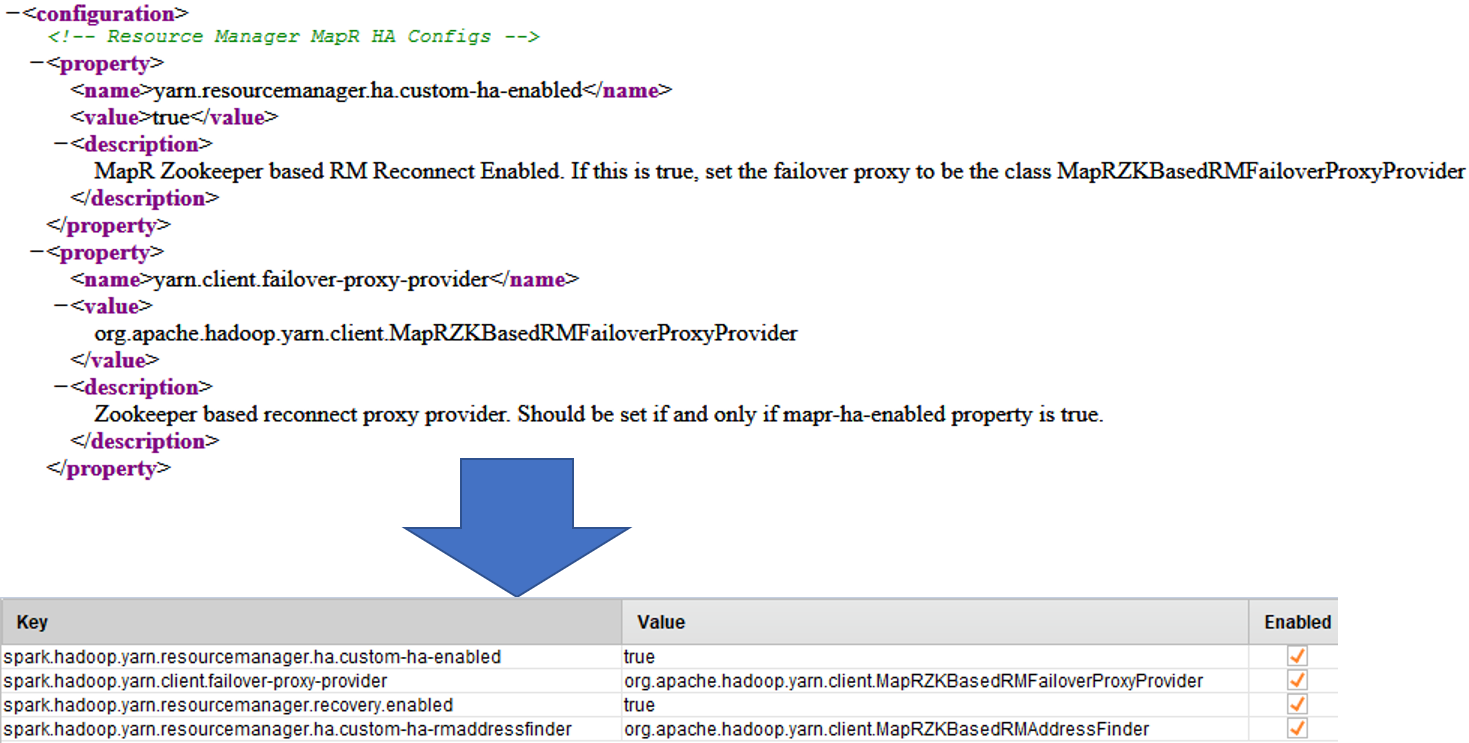
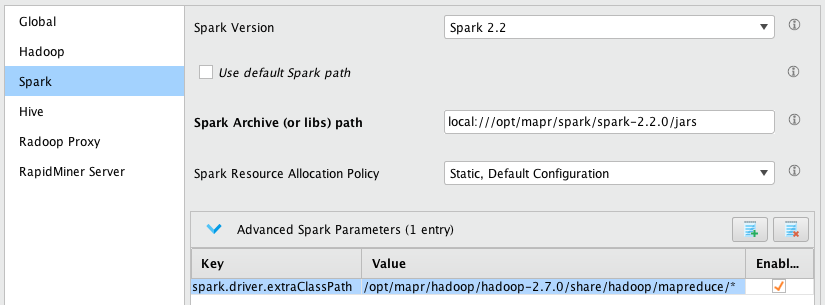
在这一点上,Spark设置可能看起来像这样。


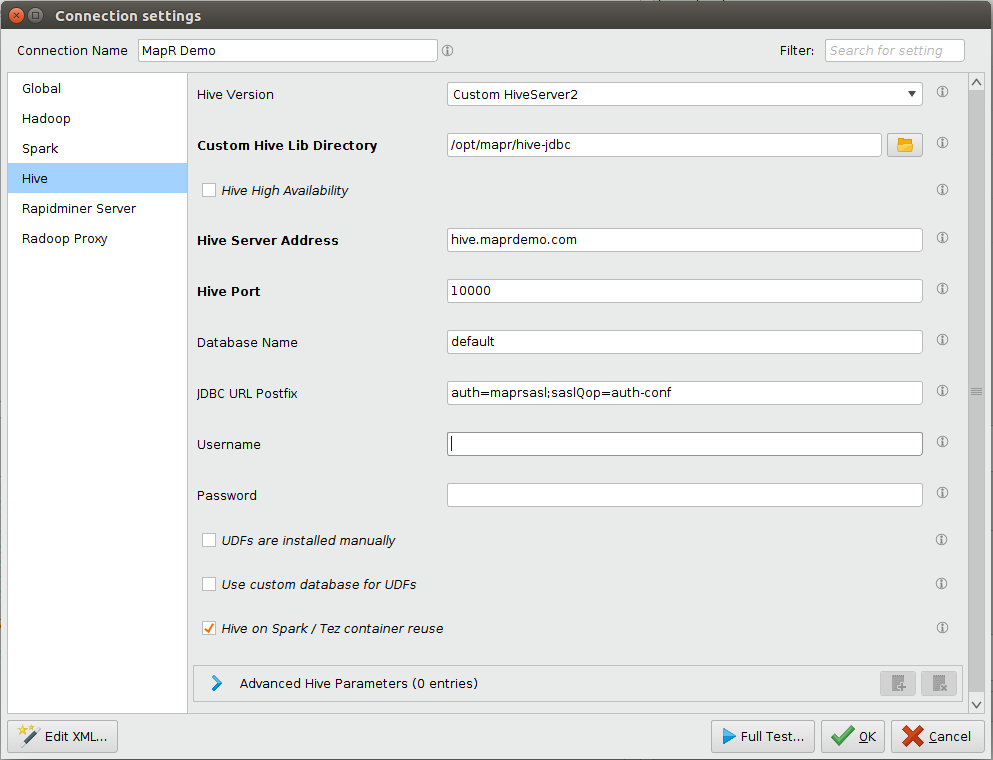
蜂巢选项卡
- 取决于Hive的安全设置
- 如果MapR安全未启用
- 为蜂巢版选择HiveServer2 (Hive 0.13或更新版本)
- 如果您的HiveServer2实例由MapR安全
- 为蜂巢版选择自定义HiveServer2
- 在自定义Hive Lib目录选择在第2步中将jar复制到的目录设置客户端机器部分。
- 为JDBC URL后缀附加
auth = maprsasl; saslQop = auth-conf到文本框。如果Hive服务器设置了SSL,请查看Hive SSL设置在Notes中
- 此外,如果您的HiveServer2实例使用SSL进行保护,则需要一个信任存储库和一个可选的信任存储库密码。对此用户需要调整JDBC URL后缀连接领域。
- 如果没有将信任库传递到正在运行的JVM中,则需要添加user
ssl = true; sslTrustStore = < path-to-truststore >; sslTrustStorePassword = <密码> - 如果JVM知道信任库,则用户只需要追加
ssl = true。可以通过以下方式将信任库安装到JVM中- 将受信任的MapR证书安装到默认的Java Keystore中。
- 包括
-Djavax.net.ssl.trustStore = < path-to-trust-store-file > -Djavax.net.ssl.trustStorePassword = <密码>到Rapidminer Studio/Server JVM启动命令。
- 如果没有将信任库传递到正在运行的JVM中,则需要添加user
- 如果MapR安全未启用
输入并验证蜂巢的地址和蜂巢港口字段。
输入您的登录凭据蜂巢的用户名和蜂巢的密码字段。提供蜂巢的用户名必须是集群上已存在的标识。请注意,根据集群设置,这些字段可以为空。
在这一点Hive设置可能看起来像这样。

在完成上述所有选项卡的设置后快速测试和完整的测试新创建的连接应该通过,没有错误。
关于在服务器上配置用户模拟的注意事项
对于RapidMiner Server,用户模拟使得在集群中充当不同的用户成为可能。该用户将始终是经过Server认证的实际RapidMiner Server用户。因此,允许访问MapR集群的Server用户也必须存在于集群中。
由于Windows MapR客户端不支持用户模拟,因此从安装在Windows机器上的RapidMiner Server连接到具有多个用户的MapR集群目前是不可能的。
遵循Radoop on Server指南的说明设置Radoop连接。
获取一个可以在所有Job Agent主机上模拟其他用户的长期MapR票证。以下命令只是示例,请参考MapR文档了解更多信息。注意,您必须确保Job Agents看到MAPR_TICKETFILE_LOCATION环境变量(您可能需要为此修改其启动脚本)。为生成的票据设置适当的文件权限,使其不能被未经授权的用户访问。您可能还需要调整相关设置,参见解析用户名的相关设置。
maprlogin password maprlogin generateticket type servicewithimpersonation -out /var/tmp/impersonation_ticket -duration 30:0:0 -renew 90:0:0 export MAPR_TICKETFILE_LOCATION=/var/tmp/impersonation_ticket
使用默认设置连接到IBM开放平台(IOP)集群通常无需在服务器上进行任何特殊设置即可工作连接设置对话框。选择IBM开放平台4.1+作为Hadoop版本,并提供适当的地址字段。如果您的集群启用了基于SQL标准的Hive授权,或者出现任何意外错误,请参考Hortonworks数据平台描述。