您正在查看9.4 -版本的RapidMiner Radoop文档点击这里查看最新版本
加载数据指南
理想情况下,您的数据已经驻留在集群上。如果是这种情况,导入并不意味着数据的移动,而是允许Radoop访问数据的对象创建。如果集群上没有数据,则导入涉及从客户机复制数据。在任何一种情况下,数据导入都可以是您的Radoop流程的一部分。
本节使用以下操作符:
- 读CSV
- 读数据库
- Hive存储
- 附加到Hive中
- 从Hive取回
每个都在上下文中简要描述;有关更多详细信息,请参见运营商或者操作员帮助文本。
RapidMiner Radoop主要使用蜂巢作为Hadoop之上的数据仓库层。要将数据的结构定义为流程中的输入,请使用Radoop的操作符和向导。易于使用的界面有助于管理数据库对象,而可视化工具可让您快速浏览它们。
导入场景
在设计导入流程时,请从以下基本场景中进行选择:
为HDFS、Amazon S3或Azure HDInsight上的数据定义一个Hive外部表。不涉及数据移动。
为HDFS上的数据定义一个Hive-managed表。源数据将被复制到Hive管理的HDFS目录结构中。您可以为目标表指定自定义存储格式。
为客户端机器上的本地数据定义一个hive管理的表。本地机器的数据将被复制到HDFS到Hive管理的目录结构中。注意,这可能是最慢的选项。
关于导入的执行,有两个选项:
| 选项 | 描述 |
|---|---|
| 立即启动导入 | 打开导入配置向导在Hadoop数据查看、描述源对象和目标对象,然后立即启动导入。这只建议用于外部表(立即创建)或较小的HDFS或本地源。导入配置没有保存,Radoop客户机将等待操作完成。进度条显示操作进度。 |
| 创建导入流程 | 使用设计视图,以创建包含一个或多个数据导入操作的流程。使用一个操作符从Radoop /数据访问/读取运营商集团。的读CSV接线员打开导入配置向导.的读数据库Operator打开一个类似的导入向导,用于配置从客户机访问的外部数据库导入的数据(通过客户机机器的数据流)。导入操作是在运行流程时执行的。如果您可能希望重用配置、定期导入、计划或与其他人共享导入过程,请选择此选项。 |
当您将进程数据集(ExampleSet)从客户机的操作内存加载到集群时,还有第三种选择。这是由Radoop巢操作符链—连接到其任何输入端口的每个ExampleSet都被推送到集群,并自动对巢内期望数据集作为输入的任何操作符可用。
使用导入向导
访问导入向导的最简单方法是从Hadoop数据视图。完成这些步骤后,RapidMiner Radoop会立即将数据导入到集群中。如果定义了多个集群连接,向导将提示要用于导入的连接。导入时间取决于数据的大小和与集群的连接。
请注意:本地源和集群中的文件或目录的处理过程基本相同。
有两种方法可以打开导入向导:
从Hadoop数据观点:
创建一个新流程读CSV内操作符Radoop巢操作符,然后点击导入配置向导在参数面板。在这种情况下,完成步骤只定义了操作符的导入参数;导入是在运行流程时执行的。
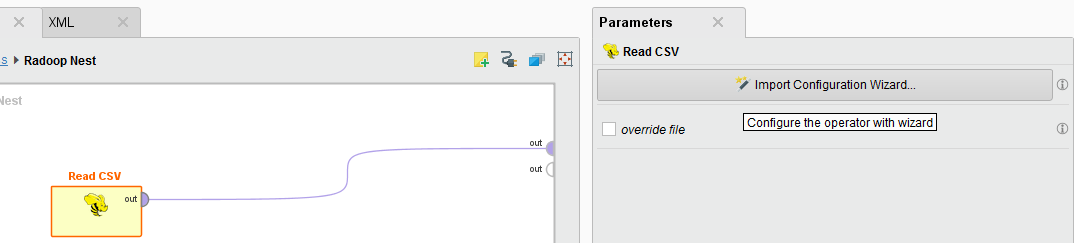


当您保存流程时,Radoop将保存使用流程文件中的向导定义的配置。如果稍后要重复导入,最好创建一个流程。
向导引导您通过以下步骤来描述源文件并在Hive(和RapidMiner)中定义目标结构。
步骤1 / 4
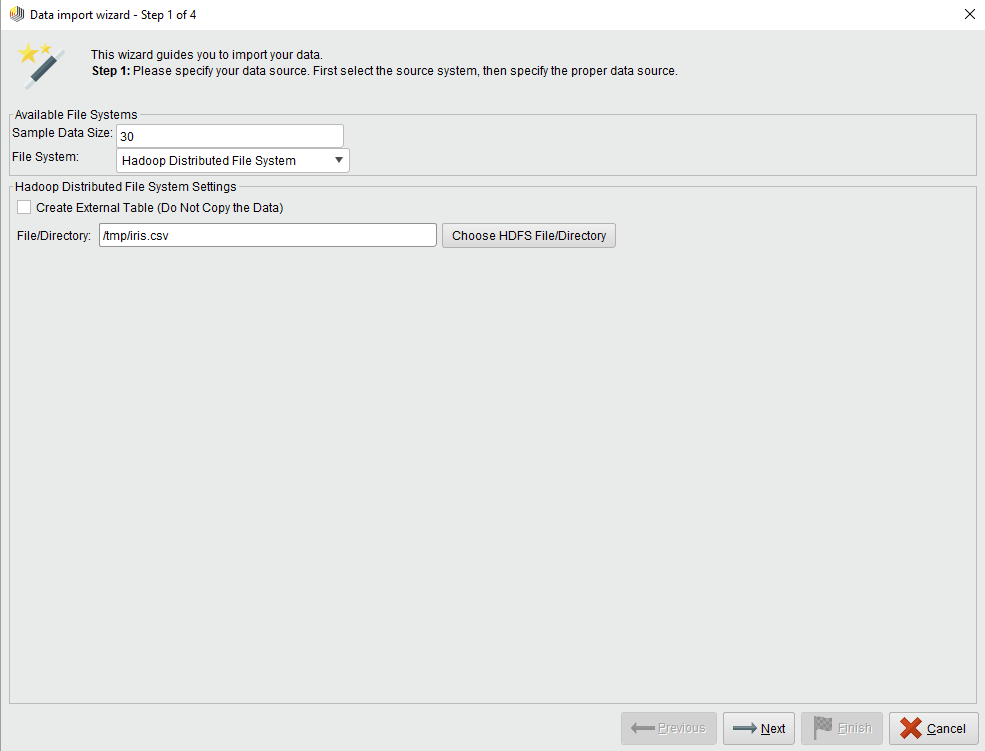
设置样本数据大小并标识文件系统。的样本数据大小指定在步骤2和3中作为数据示例显示的行数。从本地、HDFS、Amazon S3或Azure HDInsight (Blob / Data Lake)文件系统中选择。
本地文件系统
选中后,将为您提供一个打开文件浏览器的按钮。点击选择本地文件并选择输入文件或目录。点击![]() 下一个继续进行步骤2.
下一个继续进行步骤2.
Hadoop分布式文件系统
选中后,将为您提供一个打开文件浏览器的按钮。点击选择“HDFS文件/目录”并选择输入文件或目录。对于HDFS源,您可能想要创建一个外部表,您可以通过检查创建外部表…复选框。对于外部表,选择源目录;该目录中文件的内容将是外部表的内容。对于非外部(托管)表,可以选择单个文件或完整目录作为源。
点击![]() 下一个继续进行步骤2.
下一个继续进行步骤2.
Amazon Simple Storage System (S3)
指定S3路径和文件格式.根据向导中显示的说明输入路径。选择列出的标准文件格式之一。或者,选择Custom Format并完成输入和输出字段(例如,类名如org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat)。
然后,您可以测试连接并查看测试结果的日志。点击![]() 下一个继续进行步骤2.
下一个继续进行步骤2.
Azure HDInsight存储系统(Blob / Data Lake)
指定存储类型,路径和文件格式.根据向导中显示的说明,输入与所选存储类型匹配的路径。选择列出的标准文件格式之一。或者,选择Custom Format并完成输入和输出字段(例如,类名如org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat)。
然后,您可以测试连接并查看测试结果的日志。点击![]() 下一个继续进行步骤2.
下一个继续进行步骤2.
2 / 4
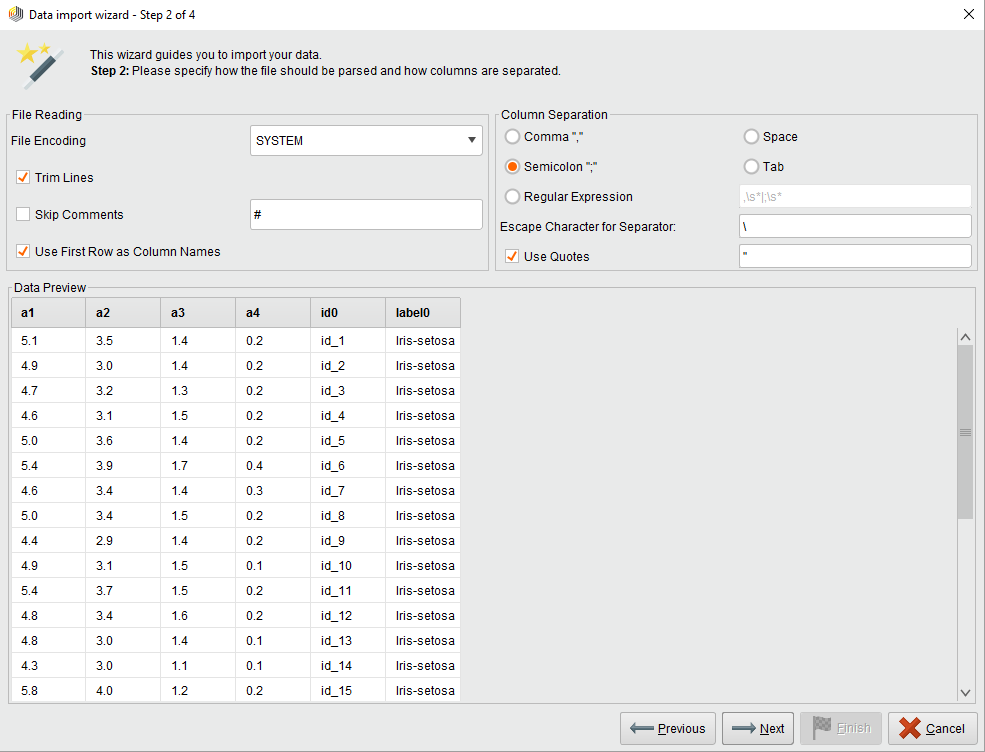
配置输入数据的格式。选择编码、列分隔符(如果需要,使用正则表达式)和其他选项,例如从第一行读取属性/列名。控件中的设置预览已解析的数据数据预览窗格。当满意时,继续下一步。
3 / 4
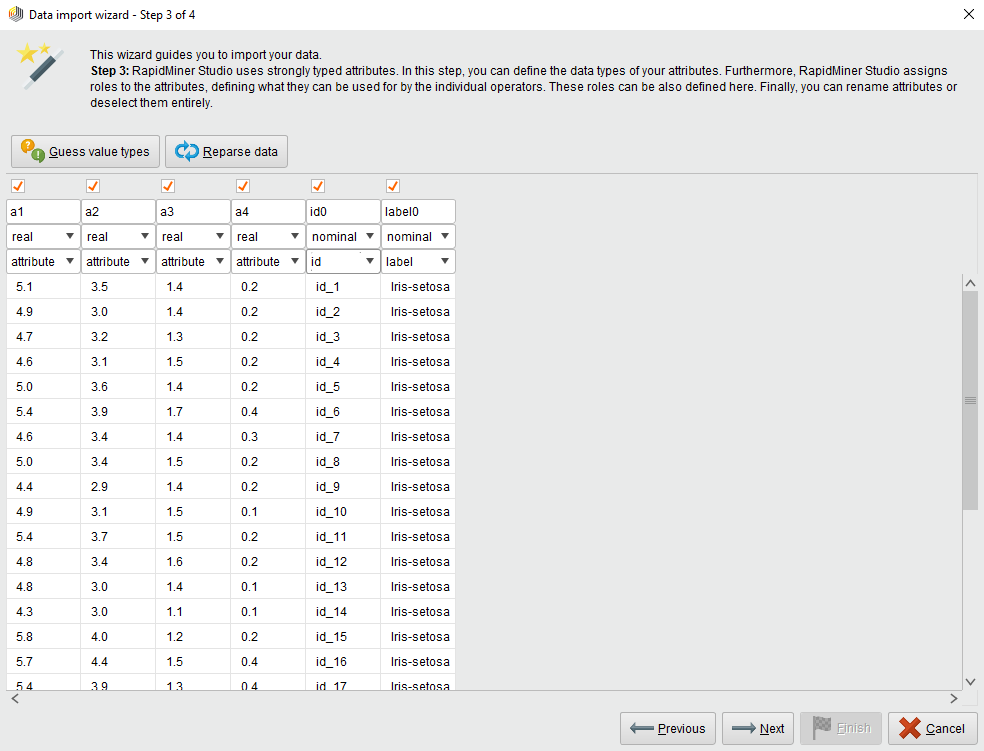
RapidMiner使用强类型属性。这个步骤有助于定义在Hive上创建的表的属性。该表对应于HadoopExampleSet。表的列是本示例集合中的属性。向导根据在文件开头找到的值猜测属性类型。允许的数据类型有:真正的,整数,名义上的和二名式命名法.RapidMiner Radoop在Hive中存储实数和整数属性作为DOUBLE和BIGINT列;标称属性存储为STRING列;二项式属性存储为STRING或布尔列。Radoop不显式地支持其他类型,但是您可以毫无问题地将DATE函数值加载到标称属性中。稍后可以使用操作符(例如,使用)处理它们生成属性),也可以使用Hive的众多DATE函数。
你也可以分配角色属性,定义单个操作符如何使用它们。也可以在稍后的流程中设置这些角色设置角色操作符。
4 / 4
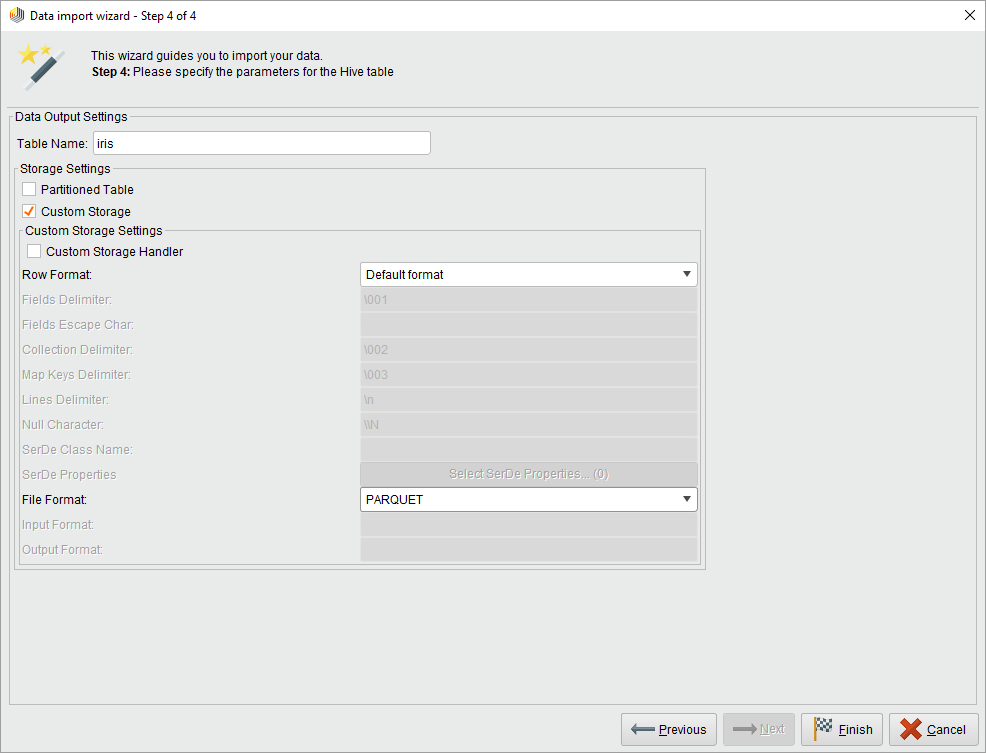
在最后一步中,为目标Hive表选择一个名称,并可选择更改存储格式。如果您打开向导从参数面板读CSV操作符时,还可以选择将数据存储在临时表还是永久表中。如果希望使用其他Radoop操作符立即处理数据,并且以后不需要这种格式的原始数据,则选择temporary。(在任何情况下,您都可以使用Hive存储操作符。)
您可以选择更改默认存储格式类定义的永久表的Fileformat蜂巢设置(或作为参数)自定义存储选择。您可以使用分区,这样在对分区列进行过滤时可以提高查询性能。特殊的存储格式可能会减少所需的空间并提高性能,但请注意,选择特殊的格式可能会增加导入运行时间,因为转换可能需要额外的开销。参考蜂巢的文档有关存储类型的详细信息。
将数据导入到集群后,可以使用Hadoop数据视图.方法访问流程中导入的数据从Hive取回操作符。右键单击此视图中的对象并单击创建流程:检索以立即创建一个使用此数据作为输入的新Radoop流程。
如果您打开了用于定义参数的向导读CSV来自设计视图中,您可以立即查看出现在操作符输出端口上的元数据(就像使用从Hive取回操作符,在选择创建的输入表之后)。
读取数据库
Radoop还可以将数据从数据库流式传输到集群。客户端从定义的数据库连接中读取数据,并立即将数据推送到集群。源可以是数据库对象,也可以是在参数中定义的查询的结果。该操作符支持连接到MySQL, PostgreSQL, Sybase, Oracle, HISQLDB, Ingres, Microsoft SQL Server或任何其他使用ODBC Bridge的数据库。
请注意:该软件可能不包含某些数据库系统的闭源JDBC驱动程序。在本例中,请下载驱动程序文件并按照以下步骤进行配置这些指令.
从内存中加载
要从客户端的操作内存中加载数据,请连接一个RapidMiner核心操作符,该操作符在其输出上传递一个ExampleSet对象Radoop巢操作符的输入。交付的数据集被推送到集群;在巢中继续处理。中更详细地描述了这个概念Radoop基础知识.
通过Hive访问数据
与Hive存储操作时,您可以在您的过程中保存当前数据集。因为a里面的数据Radoop巢始终驻留在集群上,存储实际上是指将结构和数据本身保存在Hive表中以供以后使用(即在进程完成后不删除)。存储过程并不耗时,尽管延迟计算可能必须在存储完成之前完成。
使用从Hive取回操作符访问Hive表。它在其输出端口上传递来自所选表的数据。数据驻留在集群上,直到您将Radoop操作符输出端口连接到Radoop巢.在这种情况下,从数据中获取一个样本到客户机机器的操作内存中。
如果目标表还不存在,附加到Hive中类似于Hive存储操作符。如果存在,操作符首先检查表的结构是否与其输入端口上数据集的结构相同。如果它们匹配,则将数据附加到当前目标表中。如果结构不同,系统将抛出设计时和运行时错误。