- 文档
- Radoop
- 概述
- 属性设置
RapidMiner Radoop属性设置
下表描述了影响RapidMiner Radoop操作的属性。它们被发现在RapidMiner Studio > Settings > Preferences下拉菜单对话框,在Radoop选项卡。
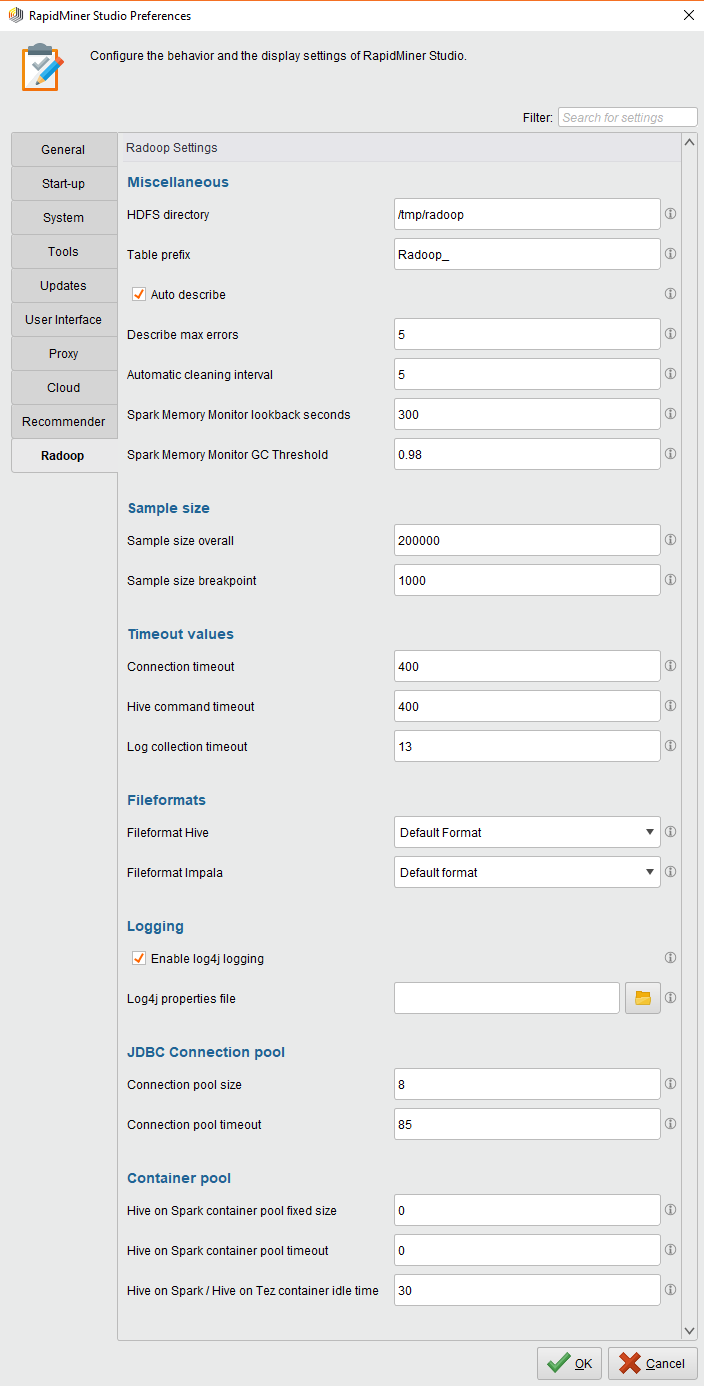
注意,每个内部键都以前缀开头rapidminer.radoop.
杂项
| 财产 |
内部关键 |
默认值 |
描述 |
| HDFS目录 |
hdfs_directory |
/ tmp / radoop / |
定义RapidMiner Radoop在HDFS目录集群中存储临时文件的位置路径。如果该目录不存在,运行RapidMiner Radoop的用户必须具有创建该目录的权限,并对该目录具有读写权限。另外,连接Hive数据库的用户需要具有读权限。请注意,不支持将此目录定位在加密区域(与Hive仓库目录不同)。 |
| 表前缀 |
table.prefix |
Radoop_ |
为新进程定义默认的Hive临时表前缀。属性覆盖该前缀Radoop巢给定进程的操作符参数,以便用户可以轻松区分集群上的临时对象。 |
| 汽车描述 |
auto_describe |
禁用 |
切换连接或刷新后是否自动描述所有Hive对象。选项上的切换按钮的状态Hadoop数据视图。Hive对象的所有元数据都是立即提取的,如果有很多对象,这可能会很慢。 |
| 描述最大错误 |
describe.max_errors |
5 |
设置错误的阈值。的Hadoop数据如果视图在描述Hive对象时遇到的错误超过此限制,则认为连接失败。你可能需要增加这个值,例如,如果你有很多Hive对象在描述时出错(例如,缺少自定义输入/输出格式类)。 |
| 自动清洗间隔 |
cleaning_interval |
5 |
间隔,以天为单位,为Radoop自动清洗服务.Radoop清除比给定阈值更早的所有临时表、文件和目录。将其设置为零将禁用自动清洗。 |
| 星火记忆监视器回顾秒 |
spark.lookbacksecs |
300 |
Spark垃圾收集使用监视器将分析的窗口大小(以秒数为单位)。 |
| Spark Memory Monitor GC threshold |
spark.gctreshold |
0.98 |
如果该百分比的时间(以回看秒为单位)用于垃圾收集,则内存监视器将终止该进程。 |
| 连接池大小 |
connection_pool_size |
8 |
Hive JDBC连接池大小。如果你想并行运行许多操作(例如在RapidMiner服务器上),请增加它。 |
样本大小
| 财产 |
内部关键 |
默认值 |
描述 |
| 总体样本量 |
sample_size.overall |
200000 |
设置Hadoop数据集在巢输出上的样本大小。的输出Radoop巢,它被提取到客户端机器的内存中。使用此值限制数据(样本)的大小。值为0表示满样本。 |
| 样本量断点 |
sample_size.breakpoint |
1000 |
在进程中的断点之后,在Hadoop data视图中设置Hadoop数据集的样本大小。当您使用断点暂停RapidMiner Radoop进程时,已处理数据的样本将被提取到客户端机器的内存中,以便手工检查。使用此值定义示例中的行数。Hadoop数据视图在浏览表时也使用了这个限制。值为0表示满样本。 |
超时值
| 财产 |
内部关键 |
默认值 |
描述 |
| 连接超时 |
connection.timeout |
30. |
设置连接的超时(以秒为单位)。此设置定义了Radoop可以取消连接测试(并认为它失败)的时间。如果连接延迟较高或间隔较大,则可能需要增加此值。0表示默认值(30秒)。 |
| Hive命令超时时间 |
hive_command.timeout |
30. |
设置允许简单Hive命令返回的超时时间(以秒为单位)。该设置定义了RapidMiner Radoop可以取消集群上原子操作的时间。如果连接延迟较高或间隔较大,请增加此值。0表示默认值(30秒)。 |
| 日志收集超时时间 |
log_collection.timeout |
30. |
设置收集YARN聚合日志的超时时间(以秒为单位)。0禁用该功能。如果您的集群禁用了YARN日志聚合功能,建议关闭此功能。 |
Fileformats
| 财产 |
内部关键 |
默认值 |
描述 |
| Fileformat蜂巢 |
fileformat.hive |
默认的格式 |
Hive连接的存储格式。存储格式通常由Radoop巢hive_file_format参数,但此属性将在新的Radoop nest中为该参数设置默认值。控件上新表导入的默认设置Hadoop数据视图。“默认格式”是指使用Hive服务器的默认格式(通常是TEXTFILE)。 |
| Fileformat黑斑羚 |
fileformat.impala |
默认的格式 |
指定Impala连接的存储格式。存储格式通常由Radoop巢impala_file_format参数,但此属性将在新的Radoop nest中为该参数设置默认值。控件上新表导入的默认设置Hadoop数据视图。“默认格式”意味着使用Impala默认格式(通常是TEXTFILE)。 |
日志记录
| 财产 |
内部关键 |
默认值 |
描述 |
| 启用log4j日志 |
log4j |
禁用 |
确定是否应该将log4j日志收集到用户文件夹中。 |
| Log4j属性文件 |
log4j . properties |
|
如果启用了log4j日志收集,并且希望使用自己的log4j。属性文件,在这里定义其位置。该文件必须包含log4j。属性,它定义了日志级别和要附加的追加程序。 |
JDBC连接池
| 财产 |
内部关键 |
默认值 |
描述 |
| 连接池大小 |
connection_pool.fast_statement.size |
8 |
Hive JDBC连接池大小。如果你想并行运行许多操作(例如在RapidMiner服务器上),请增加它。 |
| 连接池超时 |
connection_pool.fast_statement.timeout |
85 |
等待可用连接的超时时间(秒)。 |
容器池
| 财产 |
内部关键 |
默认值 |
描述 |
| Hive on Spark容器池固定大小 |
connection_pool.container.size |
0 |
设置Radoop可以使用的Spark应用上Hive的最大数量。如果设置为0,将根据集群资源估计使用容器的数量。乐鱼体育安装 |
| Hive on Spark容器池超时 |
connection_pool.container.timeout |
0 |
等待可用容器的超时时间(秒)。使用0无限期地等待资源。乐鱼体育安装 |
| Hive on Spark / Hive on Tez容器空闲时间 |
connection_pool.container.idle_time |
30. |
Tez容器上Spark / Hive上空闲Hive后的时间将关闭(秒)。使用0禁用关闭空闲容器。 |
