您正在查看9.9 -版本的RapidMiner Radoop文档点击这里查看最新版本
操作与维护
手动安装RapidMiner Radoop功能
RapidMiner Radoop功能自动安装在Radoop连接中配置的Hive数据库中。以下手册安装步骤如下只有如果不允许Radoop(更准确地说,是在Radoop连接中配置的Hadoop用户)从上传到HDFS的jar文件中创建函数,或者Hive运行在高可用模式下,则需要。
RapidMiner Radoop自动上传两个文件(radoop_hive-vX.jar和rapidminer_libs——<版本> . jar)到HDFS,并使用它们定义自定义Hive函数(udf)。对于安全的Hadoop集群,这可能是禁止的,因此Hadoop管理员需要安装这些udf。有两种方法:
- 使用Cloudera发行版时,请使用RapidMiner提供的Parcel(推荐使用);
- 手动分发和安装jar文件。
下面的两个分步指南描述了这两个选项。
第一个选项:使用Cloudera包安装jar文件
中的RapidMiner Radoop udf也可用Cloudera包裹格式。包裹可以从以下url获取。请注意,您必须选择基于的URLRapidMiner Studio / Server版本和不Radoop扩展版本。
| RapidMiner版本 | URL |
|---|---|
| 9.9(最新) | https://radoop-parcel.www.turtlecreekpls.com/latest/ |
| 9.8 | https://radoop-parcel.www.turtlecreekpls.com/9.8.0/ |
| 9.7 | https://radoop-parcel.www.turtlecreekpls.com/9.7.0/ |
| 9.6 | https://radoop-parcel.www.turtlecreekpls.com/9.6.0/ |
| 9.5 | https://radoop-parcel.www.turtlecreekpls.com/9.5.0/ |
| 9.4 | https://radoop-parcel.www.turtlecreekpls.com/9.4.0/ |
| 9.3 | https://radoop-parcel.www.turtlecreekpls.com/9.3.0/ |
| 9.1 | https://radoop-parcel.www.turtlecreekpls.com/9.1.0/ |
| 9.0 | https://radoop-parcel.www.turtlecreekpls.com/9.0.0/ |
| 8.2 | https://radoop-parcel.www.turtlecreekpls.com/8.2.0/ |
| 8.1 | https://radoop-parcel.www.turtlecreekpls.com/8.1.0/ |
| 8.0 | https://radoop-parcel.www.turtlecreekpls.com/8.0.0/ |
包裹可以通过Cloudera Manager通过点击顶部工具栏上的包裹图标安装:

在这里,您可以看到所有已安装/配置/可用的包
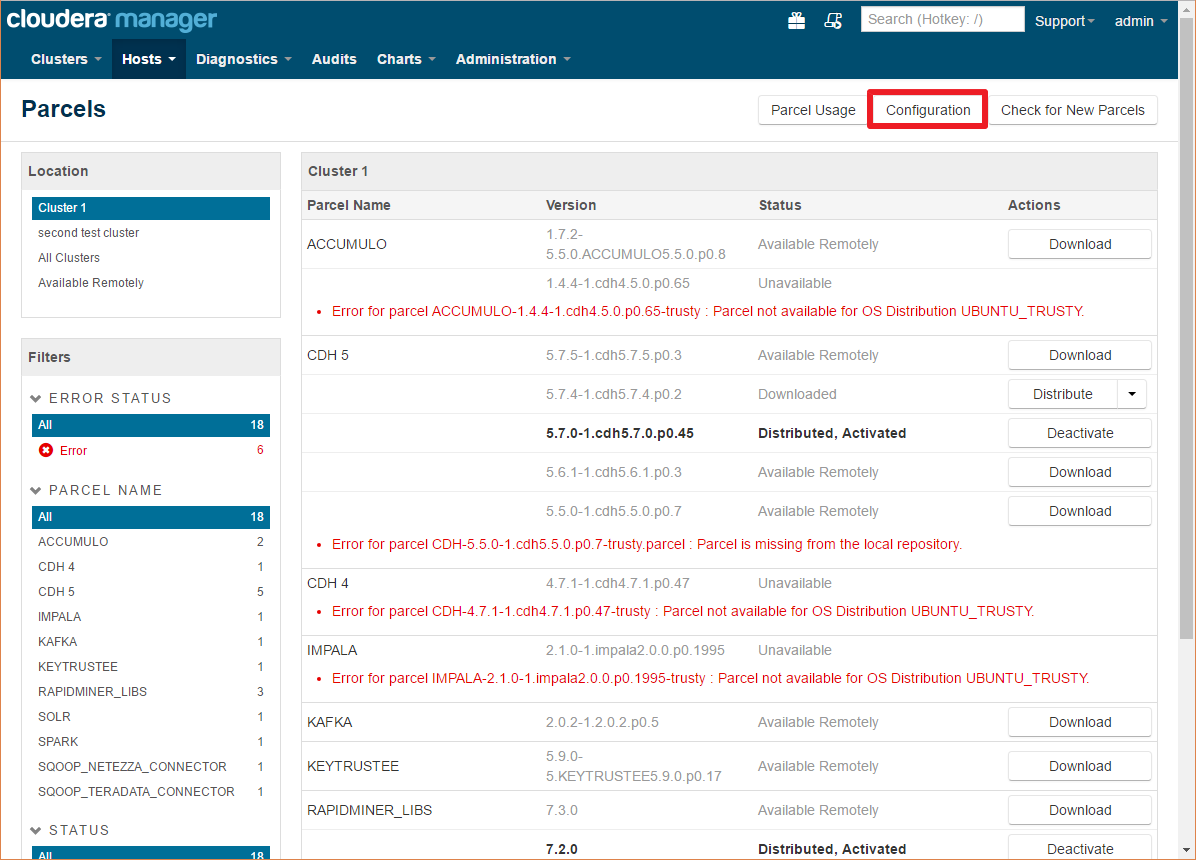
点击配置按钮,并将以下URL添加到远程包存储库url通过单击任意加号按钮列出:
https://radoop-parcel.www.turtlecreekpls.com/latest/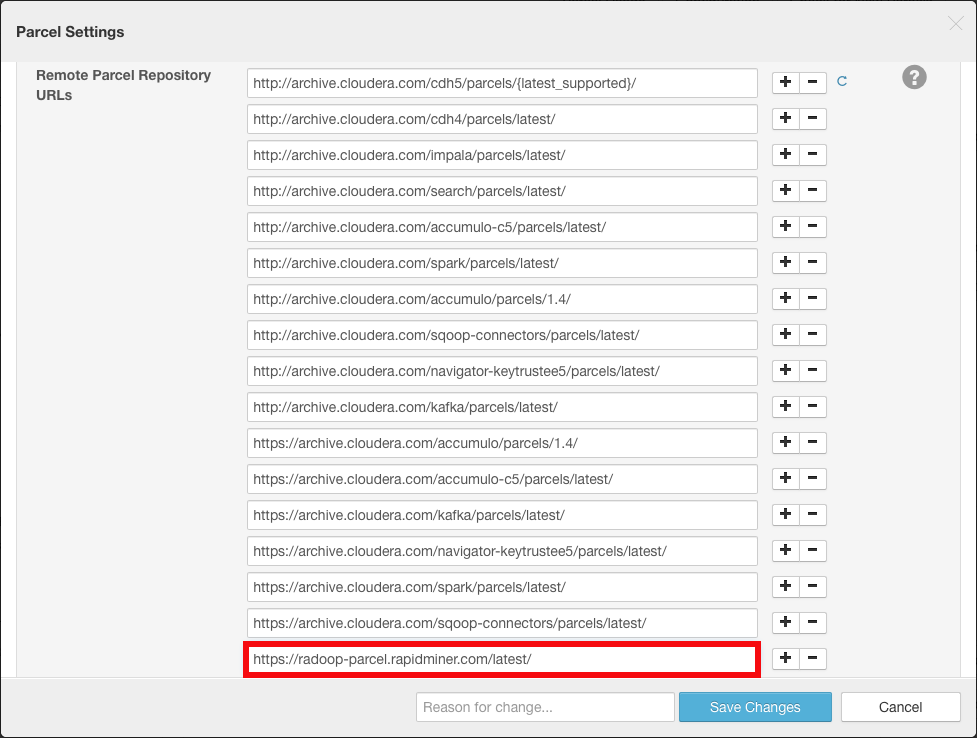
根据您的配置,您可能有多个版本的包以不同的状态列出。
点击下载最新版本


包下载后,你必须分发到节点


最后一步是激活这个包裹

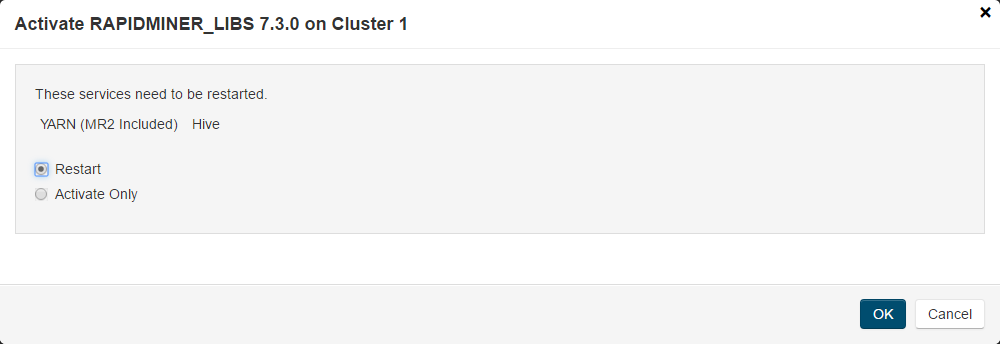
如果激活对话框中没有显示服务重启选项,说明重启成功纱和蜂巢人工服务。
在Hive中创建udf脚本匹配您的Radoop版本









有关安装和管理Cloudera包的更多信息,请访问Cloudera Manager文档
第二个选项:手动安装jar文件
RapidMiner Radoop自动上传两个文件(radoop_hive-vX.jar和rapidminer_libs——<版本> . jar)到HDFS,并使用它们定义自定义Hive函数(udf)。对于安全的Hadoop集群,这通常是被禁止的,因此Hadoop管理员需要手动安装这些udf。即使在没有安全性的Hadoop集群的情况下,出于性能原因,您也可能决定手动安装这些udf,这样就不会为每个作业分发它们。注意,在这种情况下,RapidMiner Radoop升级可能还需要手动步骤。
下载两个RapidMiner Radoop UDF JAR文件。请注意,您必须选择基于的URLRapidMiner Studio / Server版本和不Radoop扩展版本。
RapidMiner版本 链接 9.9(最新) 模型评分UDF,蜂巢UDF 9.8 模型评分UDF,蜂巢UDF 9.7 模型评分UDF,蜂巢UDF 9.6 模型评分UDF,蜂巢UDF 9.5 模型评分UDF,蜂巢UDF 9.4 模型评分UDF,蜂巢UDF 9.3 模型评分UDF,蜂巢UDF 9.1 模型评分UDF,蜂巢UDF 9.0 模型评分UDF,蜂巢UDF 8.2 模型评分UDF,蜂巢UDF 8.1 模型评分UDF,蜂巢UDF 8.0 模型评分UDF,蜂巢UDF 将下载的JAR文件复制到的本地文件系统每一个节点。每个节点上JAR文件的路径必须相同。例如,
/usr/local/lib/radoop/radoop_hive-v4.jar和/usr/local/lib/radoop/rapidminer_libs-9.9.0.jar。或者将文件复制到跨每个节点共享的HDFS位置,在这种情况下,您可以跳过其余步骤。将JAR文件添加到Hive类路径,方法是复制或链接到HIVE_HOME / lib /美元文件夹中。你必须这么做只有Hive Service所在节点。做不更改JAR文件名。
将JAR文件添加到MapReduce应用程序类路径中
mapreduce.application.classpath的财产mapred-site.xml或者在Ambari或Cloudera Manager中做同样的事情。例如,添加/usr/local/lib/radoop/radoop_hive-v4.jar: / usr /地方/ lib / radoop / rapidminer_libs-9.9.0.jar到现有值,用分隔:的性格。当使用Tez上的蜂巢,tez.cluster.additional.classpath.prefix的属性(tez-site.xml)应该改变,而不是mapreduce.application.classpath。请注意,这些属性对于某些发行版可能是空的。在此更改之后,可能需要重新启动YARN。如果修改了Hive类路径,请重启Hive Services。
在Hive中创建udf脚本匹配您的Radoop版本
升级集群时,上面的步骤可能需要再次执行,例如Ambari删除并重新创建HIVE_HOME / lib /美元文件夹中。如果不是每个节点上都存在jar文件,则会出现诸如无法找到类:eu.radoop.datahandler.hive.udf.GenericUDTFApplyModel可能会被扔。
手动创建函数
作为admin用户(或具有CREATE FUNCTION权限的用户),连接到Hive Service(例如使用Beeline),并在RapidMiner Radoop用户将使用以下命令连接的所有数据库中创建永久函数。请更改脚本第一行的数据库名称,并对所有相关数据库执行该脚本。你也有机会定义a用于Radoop udf的数据库,所有Radoop用户都应该使用(因此可以访问)。然后应该只为单个数据库创建函数。
对于Radoop连接,请检查udf是手动安装的框上的连接设置对话框。
使用radoop_user_sandbox;删除r3_add_file文件删除r3_apply_model;删除r3_correlation_matrix函数删除函数r3_esc;删除r3_gaussian_rand函数删除r3_greatest函数;删除函数r3_is_eq;删除函数r3_least;删除r3_max_index函数 DROP FUNCTION IF EXISTS r3_nth; DROP FUNCTION IF EXISTS r3_pivot_collect_avg; DROP FUNCTION IF EXISTS r3_pivot_collect_count; DROP FUNCTION IF EXISTS r3_pivot_collect_max; DROP FUNCTION IF EXISTS r3_pivot_collect_min; DROP FUNCTION IF EXISTS r3_pivot_collect_sum; DROP FUNCTION IF EXISTS r3_pivot_createtable; DROP FUNCTION IF EXISTS r3_score_naive_bayes; DROP FUNCTION IF EXISTS r3_sum_collect; DROP FUNCTION IF EXISTS r3_which; DROP FUNCTION IF EXISTS r3_sleep; CREATE FUNCTION r3_add_file AS 'eu.radoop.datahandler.hive.udf.GenericUDFAddFile'; CREATE FUNCTION r3_apply_model AS 'eu.radoop.datahandler.hive.udf.GenericUDTFApplyModel'; CREATE FUNCTION r3_correlation_matrix AS 'eu.radoop.datahandler.hive.udf.GenericUDAFCorrelationMatrix'; CREATE FUNCTION r3_esc AS 'eu.radoop.datahandler.hive.udf.GenericUDFEscapeChars'; CREATE FUNCTION r3_gaussian_rand AS 'eu.radoop.datahandler.hive.udf.GenericUDFGaussianRandom'; CREATE FUNCTION r3_greatest AS 'eu.radoop.datahandler.hive.udf.GenericUDFGreatest'; CREATE FUNCTION r3_is_eq AS 'eu.radoop.datahandler.hive.udf.GenericUDFIsEqual'; CREATE FUNCTION r3_least AS 'eu.radoop.datahandler.hive.udf.GenericUDFLeast'; CREATE FUNCTION r3_max_index AS 'eu.radoop.datahandler.hive.udf.GenericUDFMaxIndex'; CREATE FUNCTION r3_nth AS 'eu.radoop.datahandler.hive.udf.GenericUDFNth'; CREATE FUNCTION r3_pivot_collect_avg AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotAvg'; CREATE FUNCTION r3_pivot_collect_count AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotCount'; CREATE FUNCTION r3_pivot_collect_max AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotMax'; CREATE FUNCTION r3_pivot_collect_min AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotMin'; CREATE FUNCTION r3_pivot_collect_sum AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotSum'; CREATE FUNCTION r3_pivot_createtable AS 'eu.radoop.datahandler.hive.udf.GenericUDTFCreatePivotTable'; CREATE FUNCTION r3_score_naive_bayes AS 'eu.radoop.datahandler.hive.udf.GenericUDFScoreNaiveBayes'; CREATE FUNCTION r3_sum_collect AS 'eu.radoop.datahandler.hive.udf.GenericUDAFSumCollect'; CREATE FUNCTION r3_which AS 'eu.radoop.datahandler.hive.udf.GenericUDFWhich'; CREATE FUNCTION r3_sleep AS 'eu.radoop.datahandler.hive.udf.GenericUDFSleep';使用radoop_user_sandbox;删除r3_add_file文件删除r3_apply_model;删除r3_correlation_matrix函数删除函数r3_esc;删除r3_gaussian_rand函数删除r3_greatest函数;删除函数r3_is_eq;删除函数r3_least;删除r3_max_index函数 DROP FUNCTION IF EXISTS r3_nth; DROP FUNCTION IF EXISTS r3_pivot_collect_avg; DROP FUNCTION IF EXISTS r3_pivot_collect_count; DROP FUNCTION IF EXISTS r3_pivot_collect_max; DROP FUNCTION IF EXISTS r3_pivot_collect_min; DROP FUNCTION IF EXISTS r3_pivot_collect_sum; DROP FUNCTION IF EXISTS r3_pivot_createtable; DROP FUNCTION IF EXISTS r3_score_naive_bayes; DROP FUNCTION IF EXISTS r3_sum_collect; DROP FUNCTION IF EXISTS r3_which; DROP FUNCTION IF EXISTS r3_sleep; CREATE FUNCTION r3_add_file AS 'eu.radoop.datahandler.hive.udf.GenericUDFAddFile' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_apply_model AS 'eu.radoop.datahandler.hive.udf.GenericUDTFApplyModel' USING JAR 'hdfs:///rapidminer_libs-X.Y.Z.jar'; CREATE FUNCTION r3_correlation_matrix AS 'eu.radoop.datahandler.hive.udf.GenericUDAFCorrelationMatrix' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_esc AS 'eu.radoop.datahandler.hive.udf.GenericUDFEscapeChars' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_gaussian_rand AS 'eu.radoop.datahandler.hive.udf.GenericUDFGaussianRandom' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_greatest AS 'eu.radoop.datahandler.hive.udf.GenericUDFGreatest' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_is_eq AS 'eu.radoop.datahandler.hive.udf.GenericUDFIsEqual' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_least AS 'eu.radoop.datahandler.hive.udf.GenericUDFLeast' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_max_index AS 'eu.radoop.datahandler.hive.udf.GenericUDFMaxIndex' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_nth AS 'eu.radoop.datahandler.hive.udf.GenericUDFNth' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_pivot_collect_avg AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotAvg' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_pivot_collect_count AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotCount' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_pivot_collect_max AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotMax' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_pivot_collect_min AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotMin' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_pivot_collect_sum AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotSum' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_pivot_createtable AS 'eu.radoop.datahandler.hive.udf.GenericUDTFCreatePivotTable' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_score_naive_bayes AS 'eu.radoop.datahandler.hive.udf.GenericUDFScoreNaiveBayes' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_sum_collect AS 'eu.radoop.datahandler.hive.udf.GenericUDAFSumCollect' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_which AS 'eu.radoop.datahandler.hive.udf.GenericUDFWhich' USING JAR 'hdfs:///radoop_hive-v4.jar'; CREATE FUNCTION r3_sleep AS 'eu.radoop.datahandler.hive.udf.GenericUDFSleep' USING JAR 'hdfs:///radoop_hive-v4.jar'; 清理RapidMiner Radoop临时表
作为一个高级的分析解决方案,RapidMiner Radoop能够将非常复杂的过程推送到Hadoop。它在流程验证、流程执行、数据导入或全连接测试期间在Hadoop中创建临时对象(表、视图、目录、文件)。一旦不再需要这些对象,就会自动删除它们。也就是说,一旦进程或导入作业或完整连接测试完成或失败,将删除所有相关对象。
对于进程,这种默认行为可能会被改变:如果清洁的参数。Radoop巢操作符未检查,则在进程完成后不会删除这些对象。您可能想要禁用清理的唯一原因是调试。在正常操作期间,应该始终启用它,因为临时对象可能会消耗HDFS上越来越多的空间。
在正常操作期间,如果每个进程、连接测试或导入作业完成或失败,则应清理所有临时对象。然而,在少数情况下,临时对象不被删除:
- 当进程或清理阶段仍在运行时,RapidMiner Studio关闭(或服务器被杀死);
- 使用断点,因此进程停止,然后在此之后不再恢复;
- 在流程或清理阶段完成之前,连接丢失。
在这种情况下,临时物品仍然会被定期清洁服务自动清除。当使用RapidMiner Radoop运行RapidMiner Studio时,该软件会定期检查超过5天(默认情况下)的潜在剩余临时对象,并删除它找到的对象。中指定以天为单位的间隔,可以修改此服务的间隔设置/![]() 首选项/Radoop/自动清洗间隔设置。
首选项/Radoop/自动清洗间隔设置。
临时对象也可以在Hadoop Data视图上显式删除。右键单击连接,并选择菜单项清理临时数据。弹出对话框将询问它应该回顾多少天,这意味着它将考虑比这个间隔更早的对象。你可以选择0,它将删除用户的所有临时对象。请注意,如果当前有进程在此集群上运行,那么删除所有临时对象可能会中断它们的运行。弹出对话框将立即报告要删除的对象的数量。
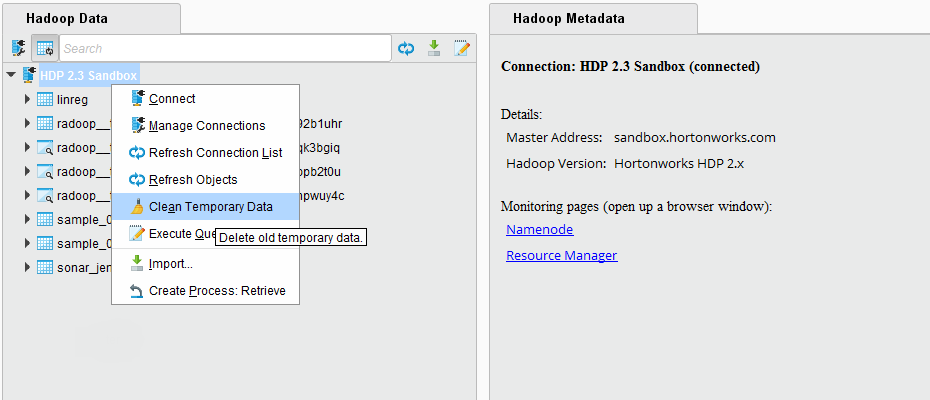
临时对象也可以由具有适当权限的用户手动删除,例如管理员。这样,你也可以删除其他用户的临时对象,这可能会破坏他们的进程运行,所以只有在你确信删除你选择的对象是安全的情况下,你才可以这样做。
临时表和视图可以很容易地与普通表和视图区分开来,因为它们使用一个共同的前缀:radoop_默认情况下。它们还包含创建对象的用户名(仅由小写字母数字字符和下划线字符组成)。该前缀可以修改。使用设置/
 首选项/Radoop/表前缀设置表前缀的参数。Radoop巢操作符更改这些临时对象的默认前缀。在Hadoop Data视图中,您可以很容易地过滤这个前缀,选择所有剩余的临时对象并删除它们。对象名称还包含时间戳,因此按升序排列将最老的对象放在最上面。
首选项/Radoop/表前缀设置表前缀的参数。Radoop巢操作符更改这些临时对象的默认前缀。在Hadoop Data视图中,您可以很容易地过滤这个前缀,选择所有剩余的临时对象并删除它们。对象名称还包含时间戳,因此按升序排列将最老的对象放在最上面。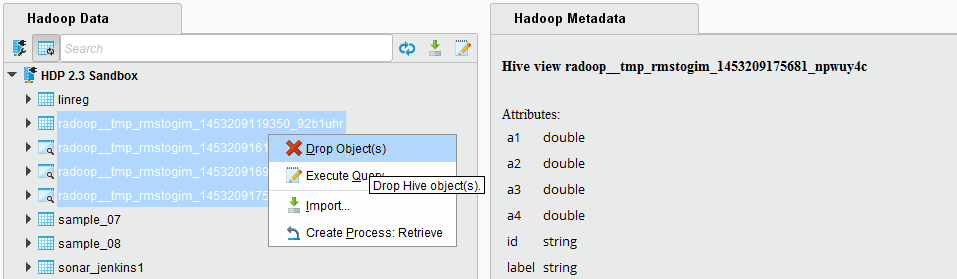
HDFS上的临时文件和目录不会显示在对象列表中,因此它们在RapidMiner Studio中不可见。剩余的临时文件不太可能占用HDFS上的大量空间,然而,Hadoop管理员可以很容易地从目录中删除它们
hdfs: / / / tmp / radoop / <用户名> /。所有临时目录名都以前缀开头tmp_。下面的命令删除特定用户的所有临时文件(replace<用户名>在命令中)。hadoop fs -rm -r -skipTrash /tmp/radoop//tmp_*
