您正在查看9.9版的RapidMiner评分代理文档点击这里查看最新版本
分数数据
后安装部署在计分代理上,您可以使用公开的web服务来计分数据。
Web服务url
的部分解释了如何创建部署,部署的每个顶级流程都可以作为计分代理上的web服务使用。通用URL定义为
http:// SA_HOST /服务/ folderName美元/ processName美元
在哪里
SA_HOST美元是计分代理的主机名(例如;localhost: 8090)folderName美元是RapidMiner服务器上部署的根文件夹(例如:score-fraud)processName美元是顶级进程的名称(例如。score-v1)
在我们的例子中,我们的评分web服务的URL看起来像这样:
http://localhost:8090/services/score-fraud/score-v1
Web服务输入
每个web服务端点都接受帖子请求application / json或文本/平原内容类型。
如果可能的话,我们建议使用JSON输入,因为它的性能比使用文本/普通输入的要好。
JSON输入
JSON输入将自动转换为ExampleSet它将提供给流程的第一个输入端口。可以提交一行数据,也可以提交多行数据。对于单行数据,JSON输入格式看起来像这样:
{“数据”({:“年龄”:“21”、“性别”:“男性”、“payment_method”:“信用卡”}]}
下面是一个示例进程,它将读取输入,应用模型,并在输出端口返回结果:
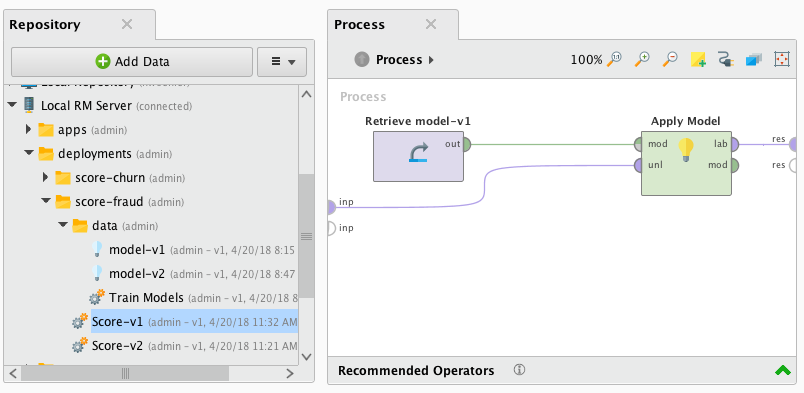
您可以使用任何HTTP命令行工具发出HTTP POST分数请求。例如,这里旋度用于发出分数请求,并使用JSON输入:
curl -H "Content-Type: application/json" -X POST -d '{"data":[{"age":"21", "gender":"male", "payment_method":"credit card"}]}' http://$SA_HOST/services/$folderName/$processName或者,您可以使用RapidMiner提供的Python包从Python调用部署的计分服务:
Import rapidminer df = pdDataFrame({“年龄”:[21],“性别”:“男性”,“payment_method”:[“信用卡”]})sc = rapidminer。得分("http://$SA_HOST", "$folderName/$processName")预测= sc.predict(df)阅读更多:RapidMiner和Python
文本输入
文本输入将作为FileObject到流程的第一个输入端口。
“年龄”、“性别”、“payment_method”21、“男性”、“信用卡”43、“女性”、“支票”
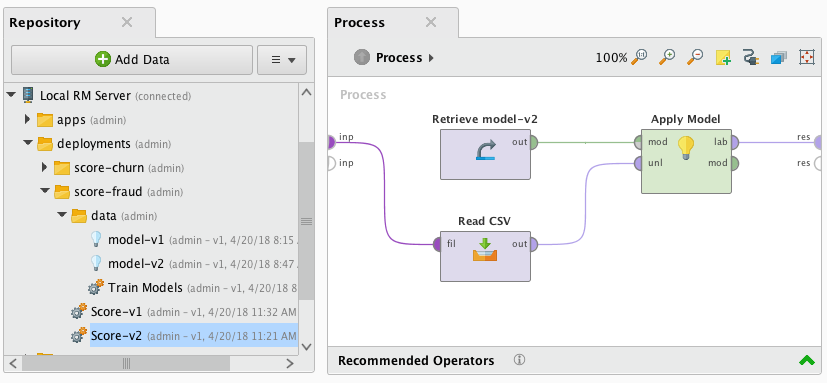
下面是一个示例进程,它将通过读CSV操作符,应用一个模型,并在输出端口返回结果:
Web服务输出
得分代理web服务的输出将始终是一个JSON表示ExampleSet它被提供给评分过程的第一个输出端口。
{“数据”:[{“年龄”:“21”、“性别”:“男性”、“payment_method”:“信用卡”、“预测(欺诈):“欺诈”、“信任(欺诈)”: 0.721,},{“年龄”:“42”,“性别”:“女性”、“payment_method”:“支票”,“预测(欺诈):“无欺诈”、“信任(欺诈)”: 0.9921,}]}
参数化的请求
如果评分流程通过RapidMiner进程的上下文声明宏,则可以通过查询参数对Web服务请求进行参数化。
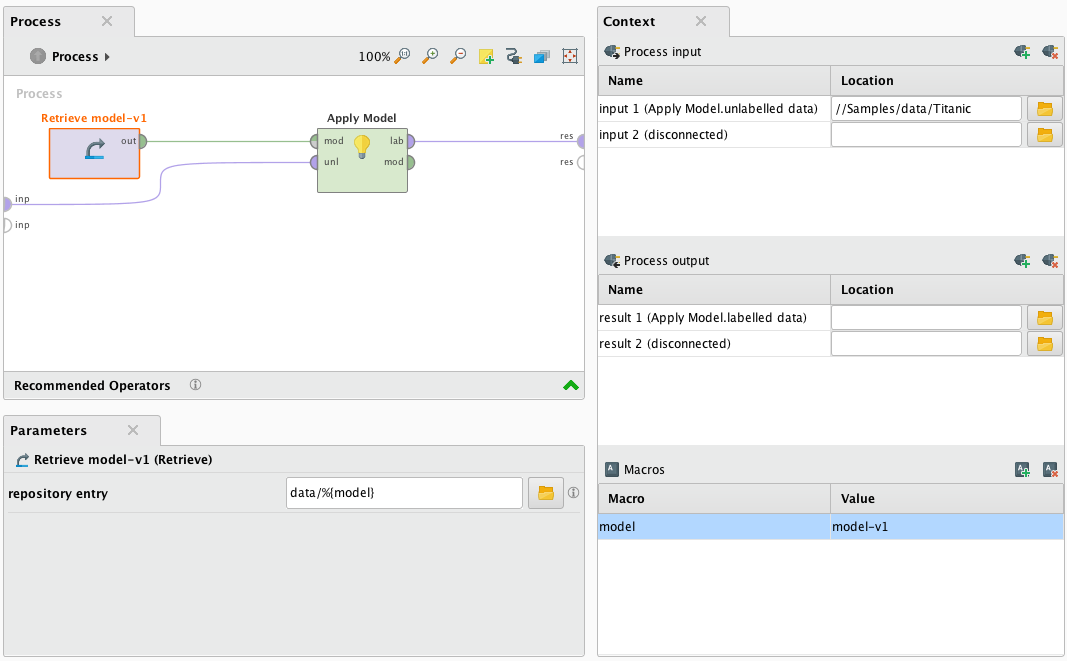
在给定的示例中,声明了一个宏模型,并在Retrieve model操作符中使用它来动态加载模型。
每个上下文宏都可以在评分请求期间通过相同名称的查询参数进行设置。例如设置模型宏是可以通过以下请求URL:
http:// SA_HOST /服务/ folderName美元/ $ processName ? = DecisionTree模型